摘要:
神经网络是一种功能强大、灵活的模型,在图像、语音和自然语言理解等许多困难的学习任务中起着很好的作用。尽管取得了成功,神经网络仍然很难设计。在本文中,我们使用递归网络来生成神经网络的模型描述,并利用强化学习来训练该RNN,最大化所生成的架构在验证集上的期望精度。在CIFAR-10数据集上,我们的方法可以从头开始,设计一种新的网络体系结构,在测试集精度方面可以与人类发明的最佳体系结构相媲美。我们的CIFAR-10模型的测试错误率为3.65,比以前使用类似架构方案的最新模型高0.09%,快1.05倍。在Penn Treebank数据集上,我们的模型可以组成一个新的递归单元,其性能优于广泛使用的LSTM单元和其他SOTA baseline。我们的单元在Penn Treebank上达到了测试集62.4的困惑度,这比之前的SOTA模型在困惑度上好3.6。该单元还可以转移到PTB上的字符语言建模任务,并达到SOTA的1.214困惑度。
方法
在这一节中,我们将首先描述一种使用递归网络生成卷积结构的简单方法。我们将展示如何使用策略梯度方法来训练递归网络,以最大化采样架构的精度的期望。我们将提出几个基于我们核心方法的改进,如形成skip连接,以增加模型的复杂性,以及使用参数服务器方法来加快训练。这一节的最后,我们将着重于生成递归架构,这是本文的另一个重要贡献。
Generate Model Descriptions with a Controller Recurrent Neural Network
在神经网络架构搜索(NAS)中,我们使用控制器生成神经网络的结构超参数。为了灵活,控制器被实现为RNN。假设我们想要预测只有卷积层的前馈神经网络,我们可以使用控制器将它们的超参数作为一系列标记生成:
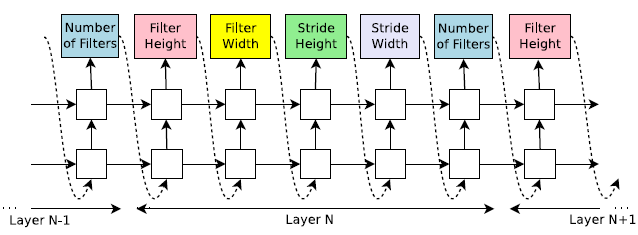
在我们的实验中,如果层的数量超过某个值,生成架构的过程就会停止。这个值遵循一个时间表,我们在训练过程中增加它。一旦控制器RNN生成了一个架构,就用这个架构建立并训练一个神经网络。收敛时,将记录持有的验证集上网络的准确性。控制器RNN的参数,$\theta_c$,接着被优化以最大化提出的架构在验证集上预测精度的期望。在下一节中,我们将描述一种策略梯度方法,用于更新参数$\theta_c$,以便控制器RNN随着时间的推移生成更好的架构。
Training with REINFORCE
控制器预测的标记列表可以看作是设计子网络架构的action的列表$a_{1:T}$。在收敛时,该子网络将在持有的数据集上达到精度$R$。我们可以用这个精度$R$作为奖励信号,用强化学习来训练控制器。更具体地说,为了找到最佳的架构,我们要求我们的控制器最大化其预期报酬,以$J(\theta_c)$表示:
由于奖励信号$R$是不可微的,我们需要使用策略梯度方法迭代更新$\theta_c$。在这项工作中,我们使用Williams(1992)的REINFORCE规则:
Accelerate Training with Parallelism and Asynchronous Updates:
