摘要
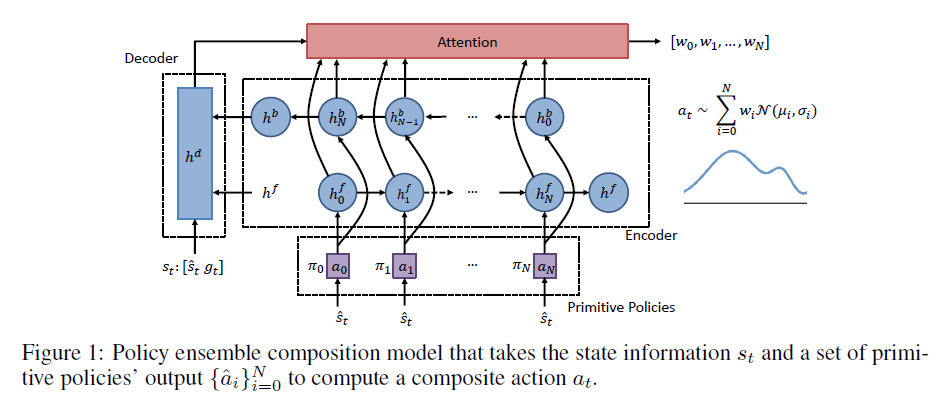
用基本行为的构成去解决迁移学习难题的是构建人工智能的关键要素之一。迄今为止,在学习task-specific的策略或技能方面已经有了大量工作,但几乎没有关注构建与任务无关的必要技能以找到新问题的解决方案。在本文中,我们提出了一种新的,基于深度强化学习的技能迁移和组合方法,该方法采用智能体的primitive策略来解决未曾见过的任务。我们在困难的环境中评估我们的方法,在这些环境中,通过标准强化学习(RL)甚至是分层RL的训练策略要么不可行,要么表现出较高的样本复杂性。我们证明了我们的方法不仅可以将技能迁移到新的问题设置中,而且还可以解决既需要任务计划又需要运动控制的挑战性环境,且数据效率很高。
论文信息

- 作者:Qureshi, A. H., Johnson, J. J., Qin, Y., Henderson, T., Boots, B., & Yip, M. C.
- 出处:ICLR2020 Poster
- 机构:UCSD
- 论文链接
- 开源代码:
- 其他资料:
内容简记