ICLR2020论文中关于强化学习的论文列表,大部分应都有收录,如有缺漏,感谢指正。
*标注的为值得精读论文
Oral(9篇)
Contrastive Learning of Structured World Models. Kipf, T., van der Pol, E., & Welling, M. (2019). [论文链接]*
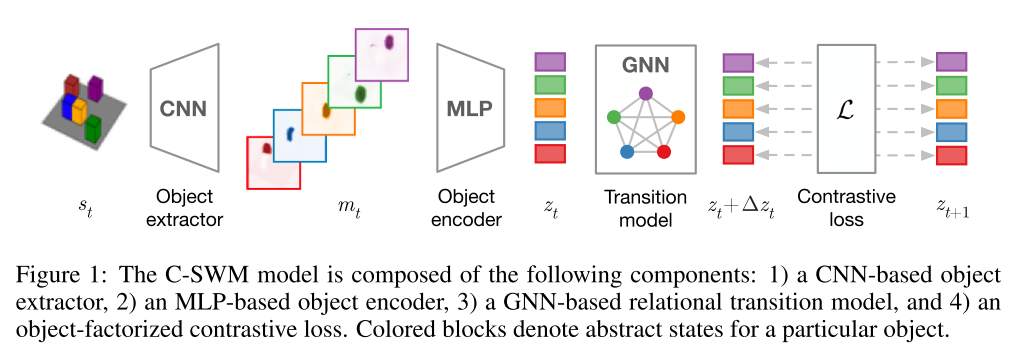
- 表示学习,图神经网络,自监督
- 从对象,关系和层次结构上对我们的世界进行结构化的理解是人类认知的重要组成部分。从原始的感知数据中学习这种结构化的世界模型仍然是一个挑战。为了朝这个目标迈进,我们引入了Contrastively-trained Structured World Models(C-SWMs)。C-SWMs利用对比方法在具有合成结构的环境中进行表示学习。我们通过图神经网络建模将每个state嵌入构造为一组对象表示及其关系。这允许模型从原始像素观察中发现对象,而无需把直接监督作为学习过程的一部分。我们在包含多个交互对象的合成环境中评估C-SWMs,这些交互对象均可以被智能体相互独立操作,包括简单的Atari游戏和多对象物理模拟器。我们的实验表明,C-SWMs可以在学习到可解释的基于对象的表示形式的基础上,克服基于像素重构的模型的局限性,并在高度结构化的环境中胜过此类模型的典型代表。
IMPLEMENTATION MATTERS IN DEEP POLICY GRADIENTS: A CASE STUDY ON PPO AND TRPO. Engstrom, L., Ilyas, A., Santurkar, S., Tsipras, D., Janoos, F., Rudolph, L., & Madry, A. (2019). [论文链接]
- OpenAI
- 强化学习实现
- 我们通过对两个流行算法(近似策略优化PPO和信任区域策略优化TRPO)的案例,研究了深度策略梯度算法中算法进步的根源。我们调研了“代码级优化”(仅在实现中发现或被描述为核心算法的辅助细节的算法增强)的结果。看起来是次要的,然而这种优化对智能体行为有重大影响。我们的结果表明,这些优化(a)贡献了PPO优于TRPO累积奖励中的大部分收益,以及(b)从根本上改变RL方法的功能。这些观察表明了在强化学习中对效果提升的归因是困难和重要的。
A CLOSER LOOK AT DEEP POLICY GRADIENTS. Ilyas, A., Engstrom, L., Santurkar, S., Tsipras, D., Janoos, F., Rudolph, L., & Madry, A. (2019). [论文链接]
- MIT
- 强化学习评估方法
- 我们研究了深度策略梯度算法的行为如何反映激励其发展的概念框架。为此,我们基于该框架的关键要素(gradient estimation, value prediction, 和optimization landscapes)提出了一种对SOTA的细粒度分析方法。我们的结果表明,深度策略梯度算法的行为通常会偏离其激励框架的预测:替代目标与真实奖励机制不匹配,学到的value estimators无法匹配真实的value function,并且gradient estimates与“真正”的梯度之间的相关性很差。我们发现的预测行为和实验行为之间的不匹配,凸显了我们对当前方法的理解不足,并表明需要超越当前以benchmark为中心的评估方法。
Meta-Q-Learning. Fakoor, R., Chaudhari, P., Soatto, S., & Smola, A. J. (2019). [论文链接]
- 元强化学习,Q-learning
- 本文介绍了Meta-Q-Learning(MQL),这是一种用于元强化学习(meta-RL)的新的off-policy算法。MQL基于三个简单的想法。首先,我们展示了如果可以访问表示过去轨迹的上下文变量,Q-learning可以匹敌最新的meta-RL算法。其次,最大化训练任务的平均奖励这样一种多任务目标是对RL策略进行元训练的有效方法。第三,元训练replay buffer中的过去数据可以被循环利用,在新任务上可以使用off-policy更新来更新策略。MQL借鉴了propensity estimation中的想法,从而扩大了可用于更新的数据量。在标准连续控制benchmark上进行的实验表明,MQL与最新的meta-RL算法相比具有优势。
POSTERIOR SAMPLING FOR MULTI-AGENT REINFORCE-MENT LEARNING: SOLVING EXTENSIVE GAMES WITH IMPERFECT INFORMATION. Zhou, Y., Li, J., & Zhu, J. (2019). [论文链接]
- 清华
- 强化学习后验采样,multi-agent,CFR
- Posterior sampling for reinforcement learning(PSRL)是在未知环境中进行决策的有用框架。PSRL维护环境的后验分布,然后在后验分布上采样的环境中进行规划。尽管PSRL在单智能体强化学习问题上表现良好,但如何将PSRL应用于多智能体强化学习问题仍待探索。在这项工作中,我们将PSRL扩展到具有不完全信息的双人零和博弈(TEGI),这是一类多智能体系统。从技术上讲,我们将PSRL与counterfactual regret minimization(CFR,这是对环境已知的TEGI上的领先算法)相结合。我们的主要贡献是互动策略的新设计。通过我们的交互策略,我们的算法可证明以$O(\sqrt{\log T / T})$的速度收敛至Nash均衡。实验结果表明,我们的算法效果很好。
Harnessing Structures for Value-Based Planning and Reinforcement Learning. Yang, Y., Zhang, G., Xu, Z., & Katabi, D. (2019). [论文链接]
- MIT
- Q函数,低秩结构
- Value-based方法是规划与深度强化学习(RL)的基本方法之一。本文中,我们建议在规划和深度强化学习中利用state-action value函数(即Q函数)的潜在结构。特别是,如果潜在的系统动态导致了Q函数的某些全局结构,则应该能够通过利用这种结构更好地推断该函数。具体来说,我们研究了低秩结构,它在大数据矩阵中广泛存在。我们在控制和深度强化学习任务的环境中通过实验验证了低秩Q函数的存在。作为我们的主要贡献,通过利用矩阵估计(ME)技术,我们提出了一个通用框架来利用Q函数中的底层低秩结构。这使得对经典控制任务的规划程序效率更高,此外,可以将简单方案应用于value-based强化学习技术,以在“低秩”任务上始终获得更好的性能。在控制任务和Atari游戏的大量实验证实了我们方法的有效性。
Fast Task Inference with Variational Intrinsic Successor Features. Hansen DeepMind, S., Dabney DeepMind, W., Barreto DeepMind, A., Warde-Farley DeepMind, D., Van de Wiele, T., & Mnih DeepMind, V. (2019). [论文链接]
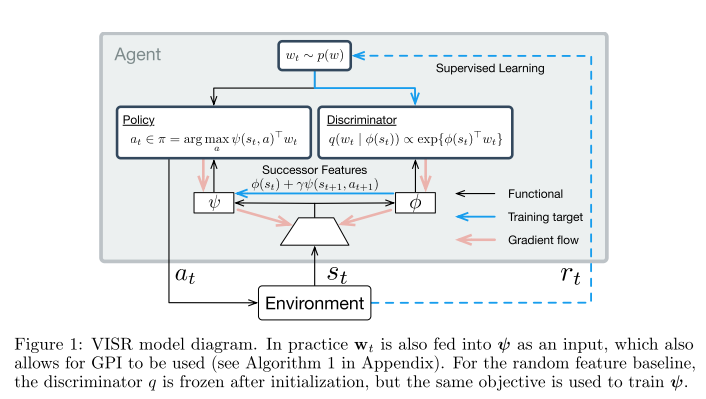
- DeepMind
- diverse behavior,Successor features
- 已经确定,张成马尔可夫决策过程可控子空间的多样性行为可以通过奖励与其他policy有区别的policy来训练(Gregor et al., 2016; Eysenbach et al., 2018; Warde-Farley et al., 2018)。但是,这种方法的一个局限性是难以推广到超出可明确学习的有限行为集的范围,而这在后续任务中可能是必需的。Successor features(Dayan, 1993; Barreto et al., 2017)提供了一个吸引人的解决方案,适用于此泛化问题,但需要在某些基础特征空间中将奖励函数定义为线性。在本文中,我们展示了可以将这两种技术结合使用,并且相互可以解决彼此的主要局限。为此,我们引入了Variational Intrinsic Successor FeatuRes(VISR),这是一种新的算法,能够学习可控特征,可通过Successor features框架利用可控特征来提供增强的泛化能力和快速的任务推断能力。我们在全部Atari套件上对VISR进行了实验验证,我们使用了新的设置,其中奖励仅是在漫长的无监督阶段之后才短暂显示。在12场比赛中达到人类水平的表现并超过所有baselines,使我们认为VISR代表了朝着能够从有限的反馈中快速学习的智能体迈出的一步。
Observational Overfitting in Reinforcement Learning. Song, X., Jiang, Y., Tu, S., Du, Y., & Neyshabur, B. (2019). [论文链接]
- Google,MIT
- 过拟合,分析框架
- 在无模型强化学习(RL)中过拟合的一个主要组成部分涉及以下情况:智能体可能会根据马尔可夫决策过程(MDP)产生的观察结果错误地将奖励与某些虚假特征相关联。我们提供了一个用于分析这种情况的通用框架,我们使用该框架通过仅修改MDP的观察空间来设计了多个综合benchmarks。当智能体过拟合到不同的观察空间(即使潜在的MDP动态是固定的)时,我们称之为observational overfitting。我们的实验揭示了有趣的属性,尤其是在implicit regularization方面,还证实了先前工作中RL泛化和监督学习(SL)的结果。
Dynamics-Aware Unsupervised Discovery of Skills. Sharma, A., Gu, S., Levine, S., Kumar, V., & Hausman, K. (2019). [论文链接]*


- Google Brain
- 传统上,基于模型的强化学习(MBRL)旨在学习环境动态的全局模型。一个好的模型可以潜在地使规划算法生成多样化的行为并解决各种不同的任务。但是,要为复杂的动态系统学习准确的模型仍然很困难,即使成功,该模型也可能无法很好地推广到训练时的状态分布之外。在这项工作中,我们将基于模型的学习与针对原语的无模型学习结合在一起,从而使基于模型的规划变得容易。为此,我们旨在回答这个问题:我们如何发现结果易于预测的技能?我们提出了一种无监督的学习算法,即“Dynamics-Aware Discovery of Skills(DADS)”,它可以同时发现可预测的行为并学习其动态。从理论上讲,我们的方法可以利用连续的技能空间,使我们即使面对高维状态空间也可以不停学习许多行为。我们证明,在学习到的潜在空间中进行zero-shot planning明显优于标准MBRL和model-free goal-conditioned RL,可以处理稀疏奖励任务,并且在无监督技能发现方面大大优于现有的分层RL方法。 我们在以下网址公开了我们的实现:https://github.com/google-research/dads
Spotlight(15篇)
DOUBLY ROBUST BIAS REDUCTION IN INFINITE HORIZON OFF-POLICY ESTIMATION. Tang, Z., Feng, Y., Li, L., Research, G., Zhou, D., & Liu, Q. (2019). [论文链接]
- Austin,Google Research
- off-policy
- 由于典型importance sampling(IS)估计量的方差过大,因此Infinite horizon off-policy policy的评估是一项极具挑战性的任务。最近,Liu et al. (2018a)提出了一种方法,该方法通过估算固定密度比来显着减少infinite horizon off-policy的评估的方差,但这是以引入密度比估计误差引起的biases为代价的。在本文中,我们开发了一种对他们方法减少bias的改进,可以利用学到的value function来提高精度。我们的方法具有双重鲁棒性,因为当密度比或value function估计完美时,bias消失。通常,当它们中的任何一个准确时,也可以减小bias。理论和实验结果均表明,我们的方法比以前的方法具有明显的优势。
INFLUENCE-BASED MULTI-AGENT EXPLORATION. Wang, T., Wang, J., Wu, Y., & Zhang, C. (2019). [论文链接]
- 清华
- transition-dependent multi-agent settings
- 内在驱动的强化学习旨在解决稀疏奖励任务的探索挑战。但是,文献中基本上没有研究transition-dependent的多主体环境中的探索方法。我们旨在朝着解决这个问题迈出一步。我们介绍了两种探索方法:exploration via information-theoretic influence(EITI)和exploration via decision-theoretic influence(EDTI),利用智能体在协作行为中的交互。EITI使用互信息来获取智能体transition dynamics之间的相互依存关系。EDTI使用一种称为Value of Interaction(VoI)的新的内在奖励来表征和量化一个智能体的行为对其他智能体的return期望的影响。通过优化EITI或EDTI目标作为正则项,鼓励智能体协调其探索和学习策略以优化集体效果。我们展示了如何优化这些正则项,以便它们可以轻松地与策略梯度强化学习集成。由此产生的更新规则在协同探索和内在reward分布之间建立了联系。最后,我们通过实验证明了我们的方法在多种多智能体场景中的强大优势。
MODEL BASED REINFORCEMENT LEARNING FOR ATARI. Kaiser, Ł., Babaeizadeh, M., Miłos, P., Zej Osí Nski, B., Campbell, R. H., Czechowski, K., … Ai, D. (2019). [论文链接]

- Google Brain
- model-based,视频预测模型
- 无模型强化学习(RL)可以用于学习复杂任务(例如Atari游戏)的有效策略,甚至可以从图像观察中学习。但是,这通常需要非常大量的交互——实际上,比人类学习相同游戏所需的交互要多得多。人是如何能如此迅速地学习?答案的部分原因可能是人们可以了解游戏的运作方式并预测哪些动作将导致理想的结果。在本文中,我们探索视频预测模型如何类似地使智能体能够以比无模型方法用更少的交互来完成Atari游戏。我们描述了Simulated Policy Learning(SimPLe),这是一种完全model-based的基于视频预测模型的深度RL算法,并提供了几种模型结构的比较,其中包括一种在我们的环境中产生最佳效果的新结构。我们的实验在智能体与环境之间进行100k次交互的低数据状态下的一系列Atari游戏中评估SimPLe,这相当于两个小时的实时播放。在大多数游戏中,SimPLe的性能优于最新的无模型算法,在某些游戏中,SimPLe的性能甚至超越一个数量级。
Behaviour Suite for Reinforcement Learning. Osband, I., Doron, Y., Hessel, M., Aslanides, J., Sezener, E., Saraiva, A., … Deepmind, H. (2019). [论文链接]
- DeepMind
- benchmark
- 本文介绍了Behaviour Suite for Reinforcement Learning,简称bsuite。bsuite是经过精心设计的实验的集合,这些实验通过两个目标研究了强化学习(RL)智能体的核心功能。首先,要收集清晰,信息丰富和可扩展的问题,以捕捉通用和高效的学习算法设计中的关键问题。第二,通过智能体在这些共享benchmark上的表现来研究他们的行为。为了补充这项工作,我们开源了https://github.com/deepmind/bsuite,可以自动评估和分析bsuite上的任何智能体。该库有助于对RL中的核心问题进行可重复且易于访问的研究,并最终设计出卓越的学习算法。我们的代码是Python,易于在现有项目中使用。我们包含了OpenAI Baselines,多巴胺以及新的参考实现的示例。未来,我们希望纳入学界的更多出色实验,并承诺定期由著名研究人员委员会审查bsuite。
EMERGENT TOOL USE FROM MULTI-AGENT AUTOCURRICULA. Baker, B., Kanitscheider, I., Markov, T., Wu, Y., Powell, G., McGrew, B., … Brain, G. (2019). [论文链接]*
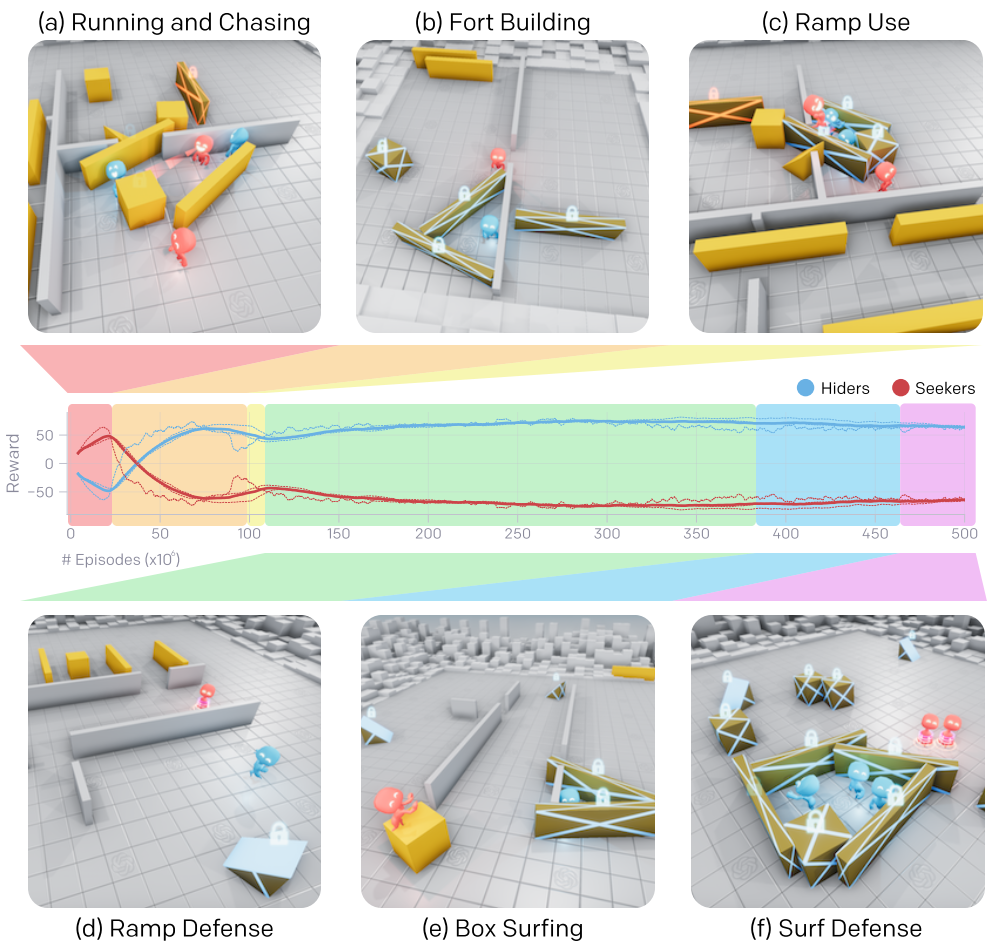
- OpenAI
- multi-agent
- 通过多智能体竞争,捉迷藏的简单目标以及大规模的标准强化学习算法,我们发现主体创建了自监督的自动课程,包含多回合不同的策略,其中许多回合需要复杂的工具使用和协作。我们发现在我们的环境中智能体策略的六个紧急阶段是显而易见的,每个阶段都会给对方团队带来新的压力。例如,智能体学会使用可移动的盒子来建造multi-object掩体,这反过来又导致智能体发现他们可以使用坡道克服障碍。我们进一步提供的证据表明,与其他自监督的强化学习方法(例如内在驱动)相比,多智能体竞争可能会随着环境复杂性的提高而更好地拓展,并导致以人类相关技能为中心的行为。最后,我们提出迁移和fine-tuning作为定量评估目标能力的一种方法,并且我们在一组特定领域的智力测验中将捉迷藏智能体和内在驱动与随机初始化baseline进行了比较。
Dream to Control: Learning Behaviors by Latent Imagination. Hafner, D., Lillicrap, T., Ba, J., & Norouzi, M. (2019). [论文链接]
- Google Brain,Deepmind
- 学习得到的世界模型总结了智能体的经验,以促进学习复杂行为。虽然通过深度学习从高维sensory输入中学习世界模型变得可行,但是仍有许多潜在的方法可以从中推导行为。我们研究了Dreamer,这是一种强化学习智能体,可以只通过潜在的想象力解决图像中的长时程任务。我们通过在学到的世界模型紧凑状态空间中想象轨迹传播学到的state values的解析梯度来有效地学习行为。(We efficiently learn behaviors by propagating analytic gradients of learned state values back through trajectories imagined in the compact state space of a learned world model.) 在完成20项具有挑战性的视觉控制任务后,Dreamer在数据效率,计算时间和最终性能方面都超过了现有方法。
SIMPLIFIED ACTION DECODER FOR DEEP MULTI-AGENT REINFORCEMENT LEARNING. Hu, H., & Foerster, J. N. (2019). [论文链接]
- Facebook AI Research
- Hanabi,向合作者提供信息
- 近年来,我们在AI的许多benchmark问题上看到了快速的进步,现代方法在Go,Poker和Dota中达到了近乎或超乎人类的表现。所有这些挑战的一个共同方面是,它们在设计上是对抗的,或者更技术地说是零和的。与这些设置相反,在现实世界中,成功通常需要人类在至少部分合作的设置下与他人合作和交流。去年,纸牌游戏Hanabi被确立为AI的新benchmark环境,以填补这一空白。特别是,Hanabi对人类很有趣,因为它完全专注于思想理论,即在观察其他玩家的行为时能够有效地推理其他玩家的意图,信念和观点的能力。强化学习(RL)面临着一个有趣的挑战,即在被他人观察时学习如何提供信息:强化学习从根本上要求智能体进行探索,以便发现良好的policy。但是,如果仅仅简单地做到这一点,这种随机性将固有地使他们的动作在训练过程中给他人提供的信息少。我们提出了一种新的深度多智能体RL方法,即Simplified Action Decoder(SAD),该方法通过集中训练阶段解决了这一矛盾。在训练过程中,SAD允许其他智能体不仅能观察所选择的(exploratory)行为,而且智能体还观察其队友的greedy行为。通过将这种简单的intuition与用于多智能体学习的最佳实现相结合,SAD在Hanabi挑战的独立游戏部分为2-5名智能体提供达到了新SOTA的学习方法。与最佳实现组件相比,我们的ablations显示了SAD的贡献。 我们所有的代码和训练好的智能体都可以在https://github.com/facebookresearch/Hanabi_SAD上找到。
IS A GOOD REPRESENTATION SUFFICIENT FOR SAM-PLE EFFICIENT REINFORCEMENT LEARNING? Du, S. S., Kakade, S. M., Wang, R., & Yang, L. F. (2019). [论文链接]
- IAS
现代深度学习方法提供了学习良好表示的有效手段。但是,良好的表示形式本身是否足以进行样本有效的强化学习?仅在更经典的近似动态规划文献中,针对(最坏情况)近似误差研究了该问题。从统计学角度看,这个问题在很大程度上尚待探讨,并且现有文献主要集中在允许样本进行有效强化学习而几乎不了解有效强化学习的必要条件的情况下。
这项工作表明,从统计学的角度来看,情况比传统的近似观点所建议的要微妙得多,在传统的近似观点中,对满足样本有效RL的表示要求更加严格。我们的主要结果为强化学习方法提供了清晰的门槛,表明在构成良好的函数逼近(就表示的维数而言)方面存在严格的限制,我们专注于与value-based, model-based, 以及policy-based的学习相关的自然表示条件。这些下限突显出,除非其近似值的质量超过某些严格的阈值,否则本身具有良好的(value- based, model-based, 或policy-based)表示不足以进行有效的强化学习。此外,这一下限还意味着样本复杂性在以下几点对比间指数级的分离:1)具有完美表示的value-based learning与具有良好但不完美表示的value-based learning;2)value-based learning与policy-based learning,3)policy-based learning和监督学习,以及4)强化学习和模仿学习。
Learning to Plan in High Dimensions via Neural Exploration-Exploitation Trees. Chen, B., Dai, B., Lin, Q., Ye, G., Liu, H., & Song, L. (2019). [论文链接]
- Georgia Tech
- 我们提出一种名为Neural Exploration-Exploitation Trees(NEXT)的元路径规划算法,以从先前的经验中学习,用来解决高维连续状态和动作空间中的新路径规划问题。与更经典的基于采样的方法(如RRT)相比,我们的方法在高维度上可获得更高的采样效率,并且可以从类似环境的规划经验中受益。更具体地说,NEXT利用一种新的神经体系结构,可以从问题结构中学习有前景的搜索方向。然后,将学习到的先验知识整合到UCB类型的算法中,以在解决新问题时实现exploration和exploitation之间的在线平衡。我们进行了彻底的实验,以表明NEXT通过更紧凑的搜索树解决了新的计划问题,并在某些benchmark上明显优于SOTA。
Making Sense of Reinforcement Learning and Probabilistic Inference. O’Donoghue, B., Osband, I., & Ionescu, C. (2020). [论文链接]
- DeepMind
- 强化学习(RL)将控制问题与统计估计结合在一起:智能体不知道系统动态,但可以通过经验来学习。最近的研究工作阐述了“RL作为推理”,并提出了一个特殊的框架将RL问题推广为概率推论。我们的论文揭示了该方法的主要缺点,并阐明了将RL连贯地转换为推理问题的意义。具体来说,RL智能体必须考虑其行为对未来reward和观察的影响:exploration-exploitation的权衡。在除最简单的设置之外的所有条件下,得出的推论在计算上都是棘手的,因此实际的RL算法必须重新近似。我们证明了流行的“RL作为推论”近似方法即使在非常基本的问题中也可能表现不佳。但是,我们展示了只需稍加修改,该框架就可以产生可证明具有良好性能的算法,并且我们表明,所得算法等同于最近提出的K学习,我们还进一步将其与Thompson采样结合在一起。
IMPROVING GENERALIZATION IN META REINFORCE-MENT LEARNING USING LEARNED OBJECTIVES. Kirsch, L., Van Steenkiste, S., & Urgen Schmidhuber, J. ¨. (2019). [论文链接]
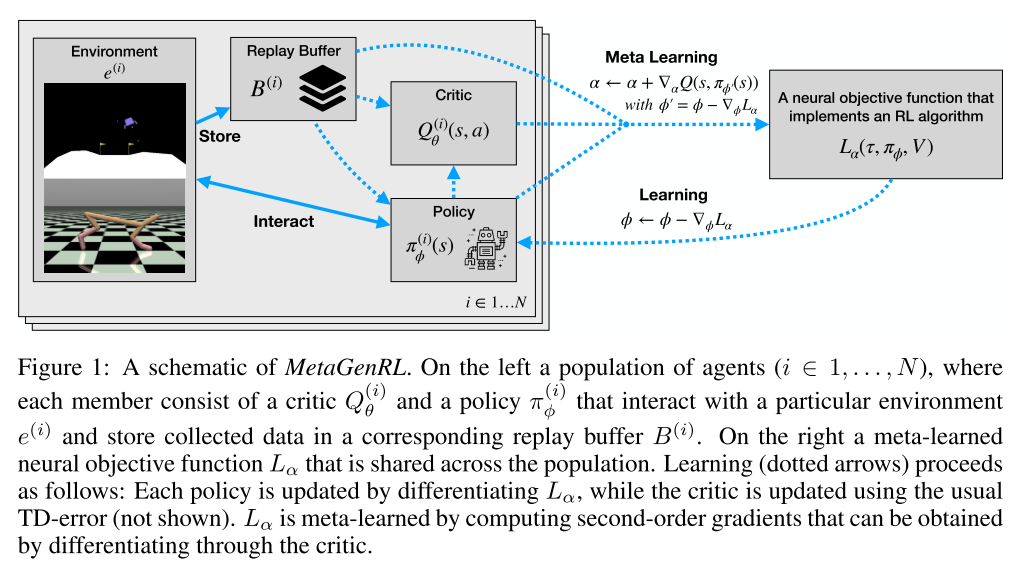
- 生物进化将许多学习者的经验提炼为人类的通用学习算法。我们新的元强化学习算法MetaGenRL受此过程启发。MetaGenRL提取了许多复杂智能体的经验,元学习一种低复杂度的神经目标函数,该函数决定了个体在未来将如何学习。与最近的元强化算法不同,MetaGenRL可以推广到与元训练阶段完全不同的新环境。在某些情况下,它甚至优于人工设计的RL算法。MetaGenRL在元训练期间使用off-policy二阶梯度,可大大提高其样本效率。
Maximum Likelihood Constraint Inference for Inverse Reinforcement Learning. Scobee, D. R. R., & Sastry, S. S. (2019, September 25). [论文链接]
- UCB
- 尽管逆强化学习(IRL)问题的大多数方法都集中在估计可以最好地解释专家的policy或在控制任务上的演示行为的奖励函数,但通常情况下,这种行为可以通过简单奖励结合一系列严格的约束更简洁地表示。在这种情况下,智能体正试图在这些给定的行为约束框架下最大化累积奖励。我们对马尔可夫决策过程(MDP)上的IRL问题进行了重新表述,以便在给定环境的nominal模型和nominal奖励函数的情况下,我们寻求在激励了智能体行为的环境中估计状态,动作和特征约束条件。 我们的方法基于最大熵IRL框架,这使我们能够根据我们对MDP的了解来推断专家演示的似然。使用我们的方法,我们可以推断能将哪些约束添加到MDP,以最大程度地增加观察这些演示得到的似然。我们提出了一种算法,该算法可迭代地推断最大似然约束以最好地解释观察到的行为,并且我们将使用模拟行为和在障碍物附近行走的人类记录数据来评估其效果。
THE INGREDIENTS OF REAL-WORLD ROBOTIC REINFORCEMENT LEARNING. Zhu, H., Yu, J., Gupta, A., Shah, D., Hartikainen, K., Singh, A., … Levine, S. (2019). [论文链接]*
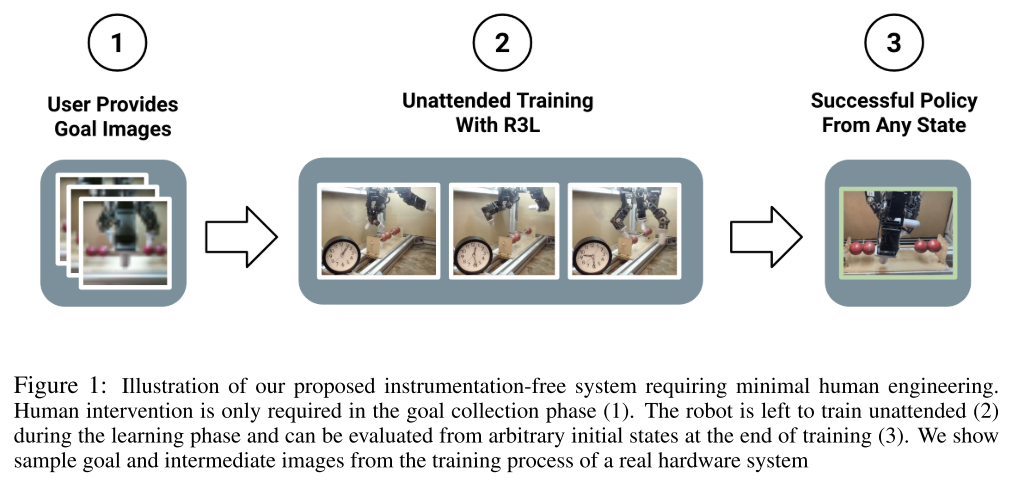
- UCB
- 在现实世界中,强化学习的成功仅限于仪器化的实验室场景,通常需要艰苦的人工和监督才能实现持续学习。在这项工作中,我们讨论了可以不断地,自主地通过现实世界中收集的数据进行改善的机器人学习系统所需的要素。我们使用dexterous manipulation作为案例研究,提出了这样一个系统的特定实例。随后,我们研究了在没有仪器的情况下学习时会遇到的许多挑战。在这种情况下,学习必须在无需人工设计的复位,仅使用板载感知器并且没有手工设计的奖励函数条件下仍然是可行的。我们提出了针对这些挑战的简单且可扩展的解决方案,然后证明了我们提出的系统在一组机器人dexterous manipulation任务上的有效性,从而提供了与该学习范式相关的挑战的深入分析。我们证明,我们的完整系统可以在没有任何人工干预的情况下进行学习,并通过真实的三爪机器人获得各种基于视觉的技能。
Measuring the Reliability of Reinforcement Learning Algorithms. Chan, S. C. Y., Fishman, S., Canny, J., Korattikara, A., & Guadarrama, S. (2019). [论文链接]
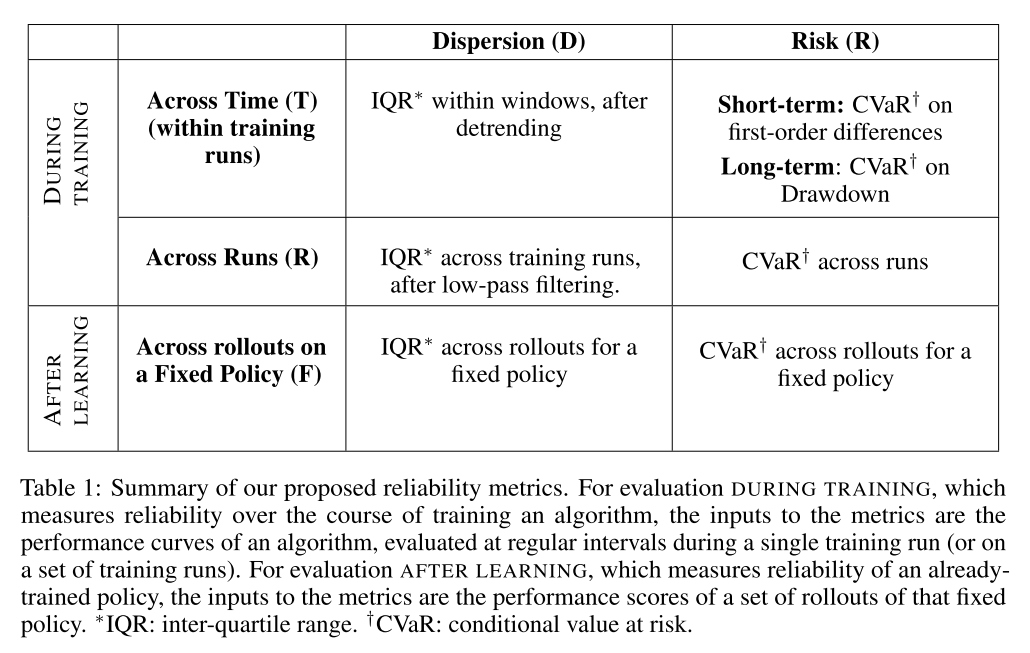
- Google Research
- 缺乏可靠性是强化学习(RL)算法的一个众所周知的问题。近年来,这个问题已引起越来越多的关注,并且为改善它而进行的努力已大大增加。为了帮助RL研究人员和生产用户评估和提高可靠性,我们提出了一套可定量测量可靠性各个方面的指标。在这项工作中,我们专注于训练期间和学习后(固定policy)的变异性和风险。我们将这些指标设计为通用的,还设计了补充统计测试以对这些指标进行严格的比较。在本文中,我们首先描述度量标准及其设计的期望属性,度量标准的可靠性方面以及它们在不同情况下的适用性。然后,我们描述统计测试并为报告结果提出其他实用建议。度量标准和随附的统计工具已作为开源代码库https://github.com/google-research/rl-reliability-metrics提供。我们将度量标准应用于一组通用RL算法和环境,进行比较并分析结果。
DISAGREEMENT-REGULARIZED IMITATION LEARNING. Brantley, K., Sun, W., & Henaff, M. (2019). [论文链接]
- Microsoft Research
- 我们提出了一种简单有效的算法,旨在解决模仿学习中的协变量偏移问题。它进行如下操作:通过在专家演示数据上训练一组集成policy,然后将其预测的方差作为cost,通过RL与有监督的行为克隆cost一同最小化。与对抗式模仿方法不同,它使用易于优化的固定奖励函数。我们证明了该算法的regret界,该算法在时域内是线性的,乘以一个对于行为克隆失败的某些问题显示为低的系数。我们在多个基于像素的Atari环境和连续控制任务上对算法进行了实验评估,结果表明该算法与行为克隆和生成对抗模仿学习相近或明显胜过。
Poster
Graph Convolutional Reinforcement Learning. Jiang, J., Dun, C., Huang, T., & Lu, Z. (2018). [论文链接]
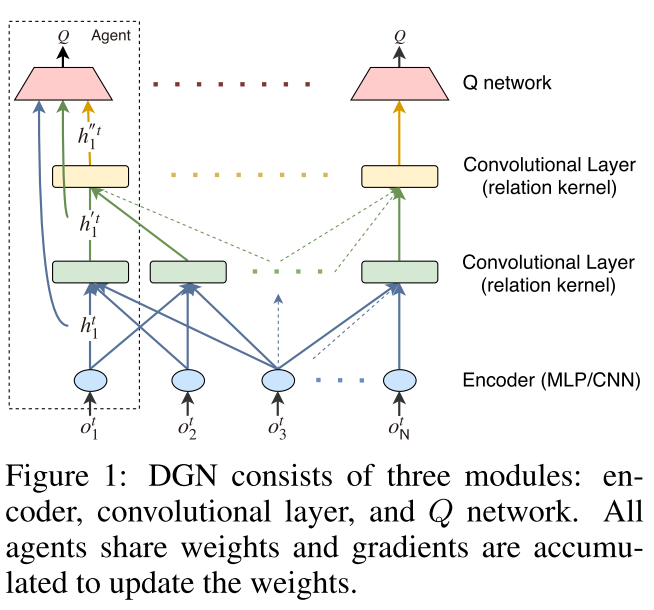
- 北大
- 在多智能体环境中,学习如何合作至关重要。关键是要了解智能体之间的相互影响。但是,多智能体环境是高度动态的,智能体不断移动,其邻居不断改变。这使得学习智能体之间相互作用的抽象表示变得困难。为了解决这些困难,我们提出了图卷积增强学习,其中图卷积适应于多智能体环境潜在图的动态,并且关系内核通过它们的关系表示来捕获智能体之间的相互作用。利用卷积层从逐渐增加的感受野产生的潜在特征来学习协作,并且通过时间关系正则化来进一步改善协作以保持一致性。从实验结果来看,我们证明了我们的方法在各种协作方案中都大大优于现有方法。
Sharing Knowledge in Multi-Task Deep Reinforcement Learning. Eramo, C. D., Tateo, D., Bonarini, A., Restelli, M., Milano, P., & Peters, J. (2020). 1–18. [论文链接]

- 我们研究了在任务之间共享表示的好处,以便在多任务强化学习中有效使用深度神经网络。我们利用这样的假设,即从不同的任务中学习,共享共同的属性,有助于推广它们的知识,与学习单个任务相比,可以更有效地提取特征。直观地讲,当由强化学习算法使用时,所得的功能集可提供性能优势。我们通过提供理论上的保证来证明这一点,这些保证强调了方便在任务之间共享表示的条件,并将众所周知的Approximate Value-Iteration的有限时间范围扩展到了多任务设置。此外,我们通过提出三种强化学习算法的多任务扩展来补充我们的分析,这些算法是我们在广泛使用的强化学习基准上进行实验评估的结果,在样本效率和性能方面,它们比单任务同类算法有了显着改进。
SQIL: IMITATION LEARNING VIA REINFORCEMENT LEARNING WITH SPARSE REWARDS. Reddy, S., Dragan, A. D., & Levine, S. (2019). [论文链接]

- UCB
- 学习模仿演示中的专家行为可能是富有挑战性的,特别是在高维,观察连续以及动态未知的环境中。基于behavioral cloning(BC)的有监督学习方法存在分布偏移的问题:因为智能体贪婪地模仿演示的动作,它可能会由于误差累积而偏离演示的状态。近来基于强化学习(RL)的方法,例如逆强化学习(inverse RL)和生成对抗式模仿学习(GAIL),通过训练RL智能体去匹配长时程的演示来克服这个问题。由于该任务的真正奖励函数是未知的,因此这些方法通常通过使用复杂且脆弱的近似技术来参与对抗训练,从演示中学习奖励函数。我们提出了一个简单的替代方法,该替代方法仍然使用RL,但不需要学习奖励函数。关键思想是通过鼓励智能体在遇到新的、分布之外的状态时返回到演示状态,从而激励他们在很长的时间内匹配演示。为此,我们为智能体提供了在演示状态下匹配演示操作的$r=+1$的恒定奖励,以及对所有其他行为的$r=0$的恒定奖励。我们的方法,我们称为soft Q imitation learning(SQIL),可以通过对任何标准Q-learning或off-policy actor-critic算法进行少量的修改来实现。从理论上讲,我们表明SQIL可以解释为BC利用稀疏先验来鼓励长时程模仿的正则化变体。实验上,我们在Box2D,Atari和MuJoCo中的各种基于图像的以及低维的任务上,SQIL的性能优于BC,与GAIL相比也取得了相近的结果。本文证明了基于RL且具有固定奖励的简单模仿方法与使用学到奖励的更复杂方法一样有效。
MAXMIN Q-LEARNING: CONTROLLING THE ESTIMATION BIAS OF Q-LEARNING. Lan, Q., Pan, Y., Fyshe, A., & White, M. (2019). [论文链接]
- Q学习遭受过高估计bias,因为Q学习使用最大估计action value来近似最大action value。已经提出了减少过高估计bias的算法,但是我们对bias与性能如何相互作用以及现有算法减轻bias的程度缺乏了解。在本文中,我们1)强调高估bias对学习效率的影响取决于环境。2)提出Q学习的一种泛化,称为Maxmin Q-learning,它提供了一个参数来灵活地控制bias;3)从理论上表明,存在一个用于Maxmin Q-learning的参数选择,该参数选择导致无偏估计,且近似方差比Q-learning低;4)使用新的广义Q-learning框架,证明了我们的算法在tabular case下的收敛性,以及多个之前的Q-learning变体的收敛性。我们通过实验验证了我们的算法可以更好地控制toy environment中的估计bias,并且可以在几个benchmark问题上实现出色的性能。
LEARNING EXPENSIVE COORDINATION: AN EVENT-BASED DEEP RL APPROACH. Yu, R., Wang, X., Wang, R., Zhang, Y., An, B., Shi, Z., & Lai, H. (2019). [论文链接]
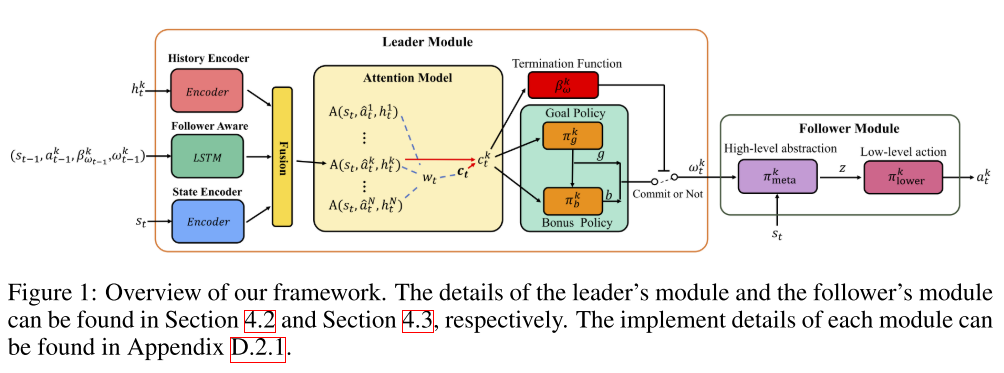
- NTU,中山大学
- 深度Multi-Agent Reinforcement Learning(MARL)中的现有工作主要着眼于协调合作智能体共同完成某些任务。 但是,在现实世界的许多情况下,智能体都是自私的,例如公司的员工和联赛中的俱乐部。因此,领导者,即公司或联盟的经理,需要向follower提供奖金,以进行有效的协调,我们称之为expensive coordination。expensive coordination工作的主要困难是:i)领导者在分配奖金时必须考虑长期影响并预测跟随者的行为,并且ii)跟随者之间的复杂互动使训练过程难以收敛,尤其是在领导者的policy会随着时间而改变。在这项工作中,我们通过基于事件的深度RL方法来解决此问题。我们的主要贡献是三方面的。(1)我们将领导者的决策过程建模为半马尔可夫决策过程,并提出一种新的multi-agent event-based policy gradient来学习领导者的长期policy。(2)我们利用leader-follower consistency scheme来设计follower-aware module和follower-specific attention module,以预测follower的行为并对其行为做出准确的响应。(3)我们提出了一种action abstraction-based policy gradient算法,以减少follower的决策空间,从而加快follower的训练过程。在资源收集,导航和捕食者-猎物游戏中进行的实验表明,我们的方法大大优于最新方法。
SVQN: SEQUENTIAL VARIATIONAL SOFT Q-LEARNING NETWORKS. Huang, S., Su, H., Zhu, J., & Chen, T. (2019). [论文链接]
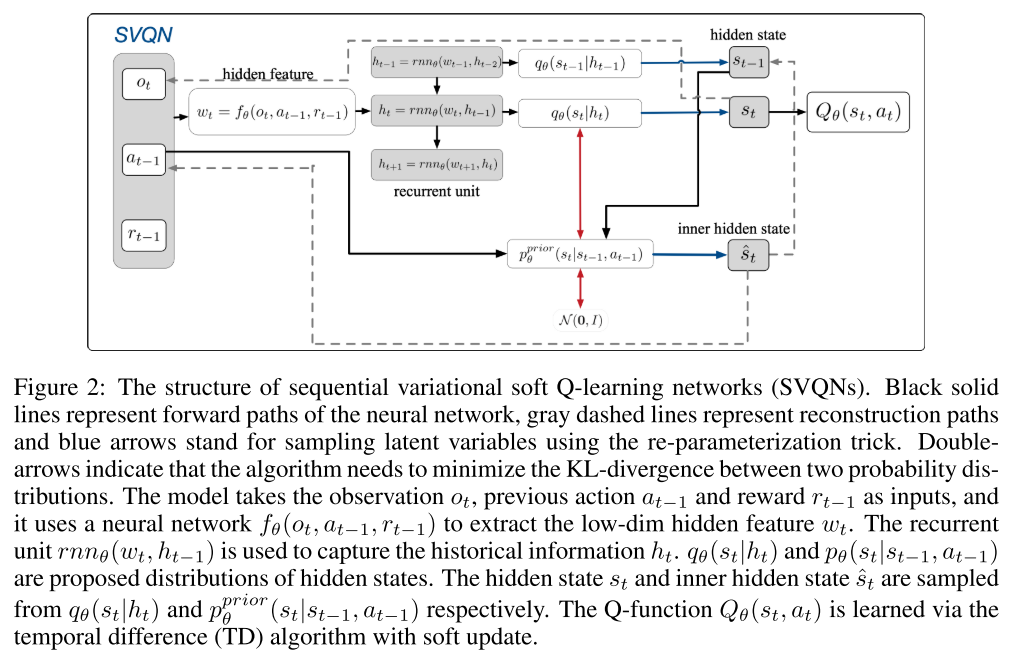
- 清华
- 部分可观察的马尔可夫决策过程(POMDP)是流行的、灵活的模型,用于现实世界中的决策应用程序,需要从过去的观察中获取信息以做出最佳决策。用于解决马尔可夫决策过程(MDP)任务的标准强化学习算法不适用,因为它们无法推断未观察到的状态。在本文中,我们提出了一种用于POMDP的新算法,称为sequential variational soft Q-learning networks(SVQN),它在统一的图模型下形式化了隐藏状态的推断和最大熵强化学习(MERL),并对两者进行了联合优化。我们进一步设计了一个深度RNN以减少算法的计算复杂度。实验结果表明,SVQN可以利用过去的信息来帮助进行有效的推理决策,并且在一些具有挑战性的任务上优于其他baseline。我们的消融实验表明,SVQN具有随时间推移的泛化能力,并且对观察的干扰具有鲁棒性。
RANKING POLICY GRADIENT. Lin, K., & Zhou, J. (2019). [论文链接]
- MSU
- 样本效率低下是强化学习(RL)中一个长期存在的问题。最先进的技术可以估计最佳action value,而通常它需要对state-action空间进行广泛搜索并进行不稳定的优化。为了实现样本效率较高的RL,我们提出了ranking policy gradient(RPG),这是一种学习一组离散action的最佳排名的策略梯度方法。为了加快对策略梯度方法的学习,我们建立了在最大化收益下限和模仿near-optimal policy而无需访问任何oracle之间的等价关系。这些结果导致了一个通用的off-policy学习框架,该框架保留了最优性,减少了方差并提高了样本效率。我们进行了广泛的实验,结果表明,与最新的policy结合时,RPG可以大大降低样本的复杂性。
A Study on Overfitting in Deep Reinforcement Learning. Zhang, C., Vinyals, O., Munos, R., & Bengio, S. (2018). [论文链接]
- 近年来,深度强化学习(RL)取得了重大进展。通过大规模的神经网络,精心设计的架构,新的训练算法和大规模并行计算设备,研究人员能够应对许多具有挑战性的RL问题。但是,在机器学习中,更多的训练能力伴随着过拟合的潜在风险。随着深度RL技术被应用于诸如医疗保健和财务等关键问题上时,了解训练好的智能体的普遍行为是重要的。在本文中,我们对标准RL智能体进行了系统研究,发现它们可能以各种方式过拟合。此外,过拟合可能“稳健”地发生:RL中常用的增加随机性的技术不一定能防止或检测到过拟合。尤其是,即使所有智能体和学习算法在训练期间都获得了最佳reward时,他们的测试性能也可能大不相同。这些发现要求在RL中使用更有原则性和更仔细评估的协议。我们以对RL过拟合的一般性讨论作为结束,并从归纳偏差的角度研究泛化行为。
Hierarchical Foresight: Self-Supervised Learning of Long-Horizon Tasks via Visual Subgoal Generation. Nair, S., & Finn, C. (2019). [论文链接]
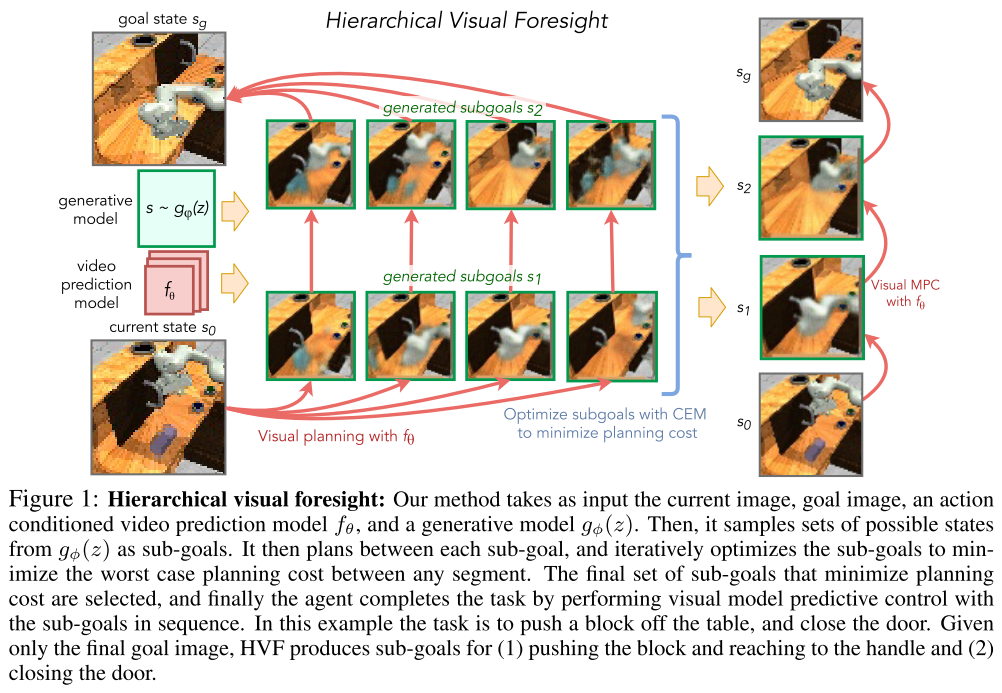
- Google Brain
- 视频预测模型与规划算法相结合已显示出使机器人能够仅通过自我监督来学习执行许多基于视觉的任务的希望,从而在杂物丛生且存在看不见物体的场景中实现了新目标。但是,由于长时程视频预测的不确定性以及sampling-based planning optimizer的可伸缩性差,这些方法的一个显着局限性在于进行长时程规划以实现远期目标。为此,我们提出了一个用于子目标生成和规划的框架,即hierarchical visual foresight(HVF),该框架可生成以目标图像为条件的子目标图像,并将其用于规划。对子目标图像进行了直接优化,以将任务分解为易于规划的部分,结果,我们观察到该方法自然会将语义上有意义的state标识为子目标。在四项基于视觉的模拟操纵任务中,有三项发现,与没有子目标和无模型RL方法的规划相比,我们的方法将性能提高了近200%。此外,我们的实验表明,我们的方法扩展到了真实,混乱的视觉场景。
MULTI-AGENT REINFORCEMENT LEARNING FOR NETWORKED SYSTEM CONTROL. Duan, Y., Schulman, J., Chen, X., Bartlett, P. L., Sutskever, I., Abbeel, P., & Science, C. (2017). (1), 1–14. [论文链接]
- Stanford
- 本文考虑了网络系统控制中的多智能体强化学习(MARL)。具体来说,每个智能体都基于local observation和来自相邻邻居的消息来学习分布式控制策略。我们将这种网络化的MARL(NMARL)问题公式化为时空马尔可夫决策过程,并引入空间discount factor来稳定每个local智能体的训练。此外,我们提出了一种新的可微通信协议,称为NeurComm,以减少NMARL中的信息丢失和非平稳性。基于现实的NMARL自适应交通信号控制和协同自适应巡航控制场景的实验,适当的空间discount factor有效地增强了non-communicative MARL算法的学习曲线,而NeurComm在学习效率和控制性能方面均优于现有的通信协议。
THE VARIATIONAL BANDWIDTH BOTTLENECK: STOCHASTIC EVALUATION ON AN INFORMATION BUDGET. Goyal, A., Bengio, Y., Botvinick, M., & Levine, S. (n.d.). [论文链接]
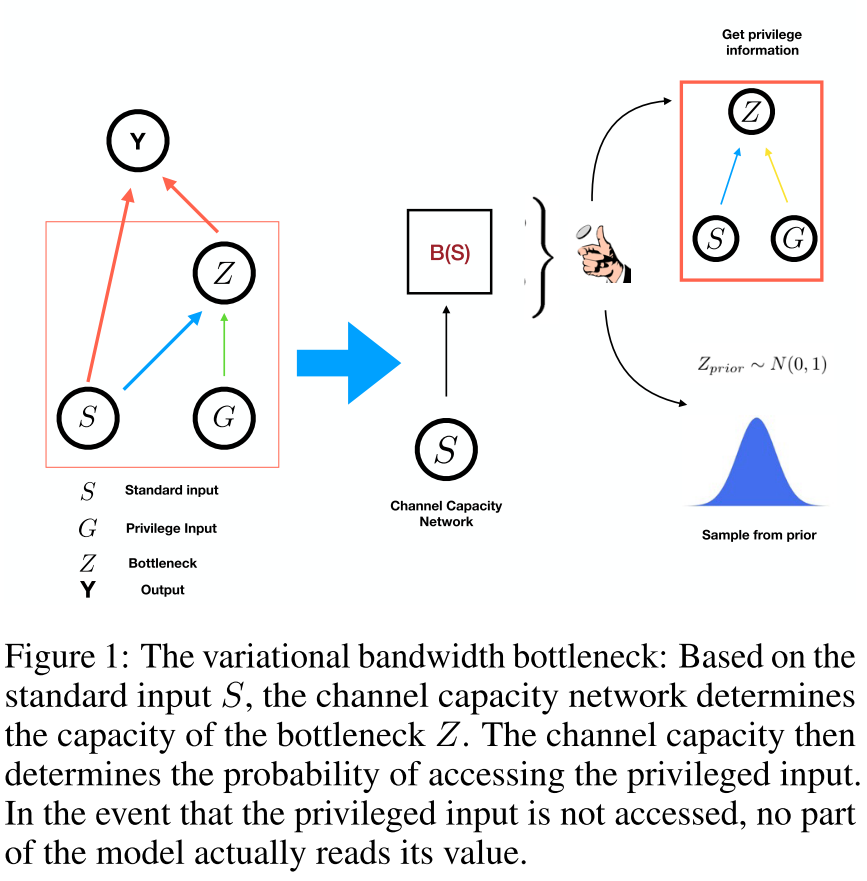
- University of Montreal,Deepmind,UCB
- 在许多应用中,期望仅从复杂的输入数据中提取相关信息,这涉及做出决定关于哪些输入特征是相关的。信息瓶颈方法通过在压缩(丢弃无关的输入信息)和预测目标之间保持最佳折衷,将其形式化为信息论优化问题。在许多问题中,包括我们在本工作中考虑的强化学习问题,我们可能更喜欢仅压缩部分输入。这种情况通常是当我们具有标准条件输入(例如状态观察)和“专用的”输入(这可能对应于任务的目标,昂贵的计划算法的输出或与其他智能体的通信)时。 在这种情况下,我们可能更喜欢压缩专用输入,以实现更好的通用性(例如,相对于目标),或者最小化对昂贵信息的访问(例如,在交流的情况下)。基于变分推断的信息瓶颈的实际实现需要访问专用输入才能计算瓶颈变量,因此,尽管它们执行压缩,但此压缩操作本身需要不受限制的无损访问。在这项工作中,我们提出了可变带宽瓶颈,该瓶颈会在查看专用信息之前就为每个示例决定专用信息的估计值,即仅基于标准输入,然后相应地随机选择是访问专用输入还是不访问。我们为该框架制定了一个易于处理的近似,并在一系列强化学习实验中证明了它可以提高泛化能力并减少对计算上昂贵的信息的访问。
LEARNING THE ARROW OF TIME FOR PROBLEMS IN REINFORCEMENT LEARNING. Nasim Rahaman, Steffen Wolf, Anirudh Goyal, Roman Remme, Y. B. (n.d.). [论文链接]
- 我们人类对时间的不对称发展有着天生的理解,我们可以用来高效、安全地感知和操纵环境。从中汲取灵感,我们解决了在马尔可夫(决策)过程中学习arrow of time的问题。我们将说明学到的arrow of time如何捕获有关环境的重要信息,这些信息又可以用于衡量可达性,检测副作用并获得内在的奖励信号。最后,我们提出一种简单而有效的算法来参数化当前问题,并使用函数逼近器(此处为深度神经网络)学习arrow of time。我们的实验结果涵盖了一系列离散和连续的环境,并针对一类随机过程证明了学习的arrow of time与Jordan, Kinderlehrer, and Otto (1998)提出的arrow of time概念相当吻合。
Reinforcement Learning with Competitive Ensembles of Information-Constrained Primitives. Goyal, A., Sodhani, S., Binas, J., Peng, X. Bin, Levine, S., & Bengio, Y. (2019). [论文链接] [阅读笔记]*

- UCB
- 原语生成,信息论,去中心化原语决策
- 在各种复杂环境中运行的强化学习智能体可以从其行为的结构分解中受益。通常,这是在分层强化学习的语境下解决的,往往目标是将策略分解为较低级别的原语或选项,同时较高级别的元策略针对给定情况触发适当的行为。但是,元策略仍必须在所有状态中做出适当的决定。在这项工作中,我们提出了一种策略设计,该策略设计可分解为原语,类似于分层强化学习,但没有高级元策略。相反,每个原语可以自己决定是否希望在当前状态下执行操作。我们使用信息论机制来实现此分散决策:每个原语都会选择需要多少有关当前状态的信息以做出决定,请求有关当前状态最多信息的原语被选择与环境交互。对原语进行正则化以使用尽可能少的信息,从而导致自然竞争和特异化。我们通过实验证明,该策略体系结构在泛化方面比平面策略和分层策略都有所改进。
EXPLORATION IN REINFORCEMENT LEARNING WITH DEEP COVERING OPTIONS. Jinnai, Y., Park, J. W., Machado, M. C., Brain, G., & Konidaris, G. (2019). [论文链接]

- Brown University
- 尽管已经提出了许多选择发现方法来加速强化学习中的探索,但它们常常是启发式的。最近,covering options被提出,以发现一组可证明减少了环境覆盖时间(用于衡量探索难度)上限的选项。但是,它们仅限于表格任务,不适用于具有较大或连续状态空间的任务。我们介绍了deep covering options,这是一种在线方法,可以将covering options扩展到大型状态空间,自动发现与任务无关的选项以鼓励探索。我们在几个具有挑战性的稀疏奖励域中评估了我们的方法,结果表明我们的方法识别出了状态空间中较少探索的区域,并成功地生成了访问这些区域的选择,从而极大地改善了探索和总累积奖励。
WATCH, TRY, LEARN: META-LEARNING FROM DEMONSTRATIONS AND REWARDS. Zhou, A., Jang Google Brain, E., Kappler, D., Herzog, A. X., Khansari, M., Wohlart, P., … Finn Google Brain, C. (2019). [论文链接]

- Google Brain
- 模仿学习使智能体可以从演示中学习复杂的行为。但是,学习基于视觉的复杂任务可能需要大量不现实的演示。元模仿学习是一种有前途的方法,可以使智能体通过学习类似任务的经验,从一个或几个演示中学习新任务。在任务模棱两可或没有观察到动态的情况下,仅凭演示可能无法提供足够的信息。智能体还必须尝试执行任务以成功推断策略。在这项工作中,我们提出了一种方法,该方法可以从演示和具有稀疏奖励反馈的试错经验中学习。与元模仿相比,此方法使智能体能够有效且高效地自我改进,超越了演示数据。与元强化学习相比,由于演示减轻了探索负担,因此我们可以扩展到更广泛的任务分布上。我们的实验表明,在一系列具有挑战性,基于视觉的控制任务上,我们的方法明显优于以前的方法。
V-MPO: ON-POLICY MAXIMUM A POSTERIORI POLICY OPTIMIZATION FOR DISCRETE AND CONTINUOUS CONTROL. Song, H. F., Abdolmaleki, A., Springenberg, T., Clark, A., Soyer, H., Rae, J. W., … Botvinick, M. M. (2019). [论文链接]

- DeepMind
- 一些应用于有挑战的离散和连续控制领域里最成功的深度强化学习,在on-policy设置中使用了策略梯度方法。但是,策略梯度可能会受到较大方差的影响,这可能会限制性能,并且在实践中需要仔细调整熵正则化以防止策略崩溃。作为策略梯度算法的替代方法,我们介绍了V-MPO,它是Maximum a Posteriori Policy Optimization(MPO)的on-policy变体,它基于学到的state-value函数执行策略迭代。我们展示了V-MPO在多任务设置中超过了Atari-57和DMLab-30 benchmark套件的先前报告的分数,并且在没有重要度加权,熵正则化或population-based超参数调整的情况下可靠地做到了这一点。在individual DMLab和Atari级别上,我们提出的算法可以获得比以前报告的分数更高的分数。V-MPO也适用于具有高维连续动作空间的问题,我们在学习控制具有22个全状态观察自由度和56个像素观查自由度的人体模拟的过程中证明了这一点,以及例如,OpenAI Gym任务中,V-MPO的渐近得分远高于以前报道的水平。
AUTOMATED CURRICULA THROUGH SETTER-SOLVER INTERACTIONS. Racanì, S., Lampinen, A. K., Santoro, A., Reichert, D. P., Firoiu, V., & Lillicrap Deepmind, T. P. (2019). [论文链接]
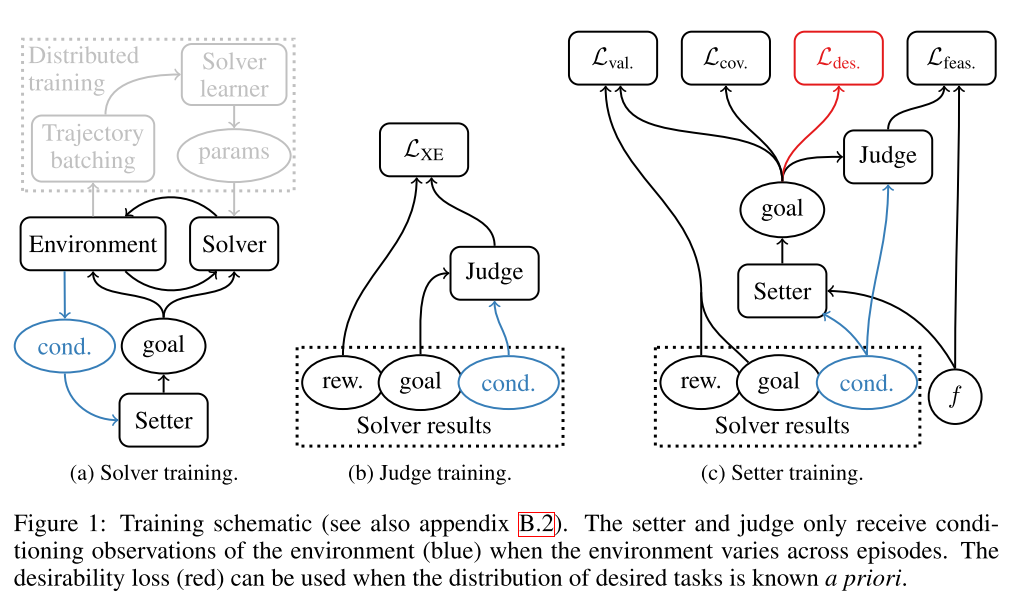
- DeepMind
- 强化学习算法使用策略和奖励之间的关联来提高智能体的性能。但是在动态或稀疏的奖励环境中,这些关联通常太小,或者奖励事件太少而无法使学习可行。相反,人类教育依靠课程(将任务分解为简单的,具有丰厚奖励的静态挑战)来建立复杂的行为。尽管课程对于人工智能体也有用,但是手工制作却很耗时。这引导了研究人员去探索自动课程的生成。在这里,我们探索了在丰富、动态的环境中自动生成课程的方法。通过使用setter-solver范式,我们展示了考虑目标有效性、目标可行性和目标覆盖范围以构建有用课程的重要性。我们展示了我们的方法在丰富但稀疏的2D和3D环境中的成功,在这种环境中,智能体要实现一个目标,该目标选自episode之间可能变化的一组可行目标,并确定未来工作的挑战。最后,我们演示了一种新技术的价值,该技术可以指导智能体朝着理想的目标分布方向发展。总而言之,这些结果代表了朝着应用自动任务课程去学习复杂的、用其他方法无法学习的目标迈出的重要一步,据我们所知,这是第一个展示可行目标在episode之间变化的环境中,为goal-conditioned智能体自动生成课程。
LEARNING SELF-CORRECTABLE POLICIES AND VALUE FUNCTIONS FROM DEMONSTRATIONS WITH NEGATIVE SAMPLING. Luo, Y., Xu, H., & Ma, T. (2019). [论文链接]
- Princeton,UCB,Stanford
- 模仿学习,再加上强化学习算法,是有希望样本有效地解决复杂控制任务的范式。然而,从演示中学习常常会遭受协变量偏移问题,这会导致所学策略的级联错误。我们引入了一个conservatively-extrapolated value function的概念,该函数可产生具有自我校正的策略。我们设计了Value Iteration with Negative Sampling(VINS)算法,该算法实际上通过conservative extrapolation来学习此类value functions。我们展示了VINS可以纠正模拟机器人benchmark任务上的行为克隆策略的错误。我们还提出了使用VINS初始化强化学习算法的算法,该算法在样本效率方面表现优于以前的工作。
EXPLORING MODEL-BASED PLANNING WITH POLICY NETWORKS. Wang, T., & Ba, J. (2019). [论文链接]
- 具有模型预测控制或在线规划的Model-based reinforcement learning(MBRL)在样本效率和渐进性能方面都显示了在运动控制任务上的巨大潜力。尽管取得了成功,但是现有的规划方法是从动作空间中随机生成的候选序列中搜索的,这在复杂的高维环境中效率不高。在本文中,我们提出了一种新颖的MBRL算法,即model-based policy planning(POPLIN),该算法将策略网络与在线规划相结合。更具体地说,我们使用神经网络将每个时间步的行动规划形式化为优化问题。我们尝试了两种优化从策略网络初始化动作序列,然后直接在线优化策略网络的参数。我们证明,在MuJoCo benchmark测试环境中,POPLIN的采样效率比以前的最新算法(例如PETS,TD3和SAC)高出约3倍。为了说明我们算法的有效性,我们证明了参数空间中的优化曲面比动作空间中的曲面更平滑。此外,我们发现对于某些环境(例如,Cheetah),在测试期间无需扩展模型预测控制的情况下,就可以有效地应用提炼策略网络。代码在此处发布https://github.com/WilsonWangTHU/POPLIN。
ADVERSARIAL POLICIES: ATTACKING DEEP REINFORCEMENT LEARNING. Gleave, A., Dennis, M., Wild, C., Kant, N., Levine, S., & Russell, S. (2019). [论文链接]
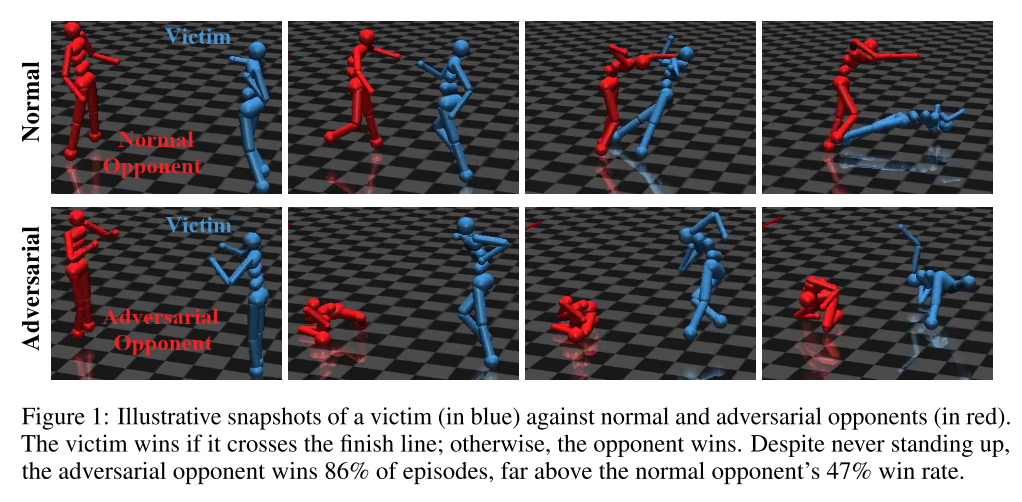
- UCB
- 众所周知,深度强化学习(RL)策略容易受到其观察结果的对抗性干扰,类似于分类器的对抗性示例。但是,攻击者通常无法直接修改其他智能体的观察结果。这可能会让人产生疑问:是否可以通过选择在多智能体环境中采取的对抗策略来攻击RL智能体,从而创建具有对抗性的自然观察结果?我们演示了在具有本体感受观察的模拟人形机器人之间的零和博弈中对抗策略的存在,对抗通过self-play训练对对手具有鲁棒性的state-of-the-art victim。对抗性政策可靠地击败了victim,但产生了看似随机和不协调的行为。我们发现,这些策略在高维环境中更为成功,并在victim策略网络中诱导出与victim对抗正常对手时完全不同的激活。微调可以保护victim免受特定对手的攻击,但是可以成功地重新应用攻击方法以找到新的对手策略。可以从https://adversarialpolicies.github.io/获得视频。
VIDEOFLOW: A CONDITIONAL FLOW-BASED MODEL FOR STOCHASTIC VIDEO GENERATION. Kumar, M., Babaeizadeh, M., Erhan, D., Finn, C., Levine, S., Dinh, L., & Kingma, D. (2019). [论文链接]
- GoogleBrain
- 原则上,可以建模和预测未来事件序列的生成模型可以学习捕获复杂的现实世界现象,例如物理交互。但是,视频预测中的一个主要挑战是,未来是高度不确定的:过去对事件的观察序列可能暗示着许多可能的未来。尽管最近的许多工作已经研究了可以表示不确定未来的概率模型,但是这种模型要么是像素级自回归模型那样在计算上非常昂贵,要么不能直接优化数据的似然。据我们所知,我们的工作是第一个提出具有normalizing flow的多帧视频预测的方法,该方法可以直接优化数据似然,并产生高质量的随机预测。我们描述了一种对潜在空间动力学进行建模的方法,并证明了基于flow的生成模型为视频生成建模提供了一种可行且具有竞争力的方法。
Variational Recurrent Models for Solving Partially Observable Control Tasks. Han, D., Doya, K., & Tani, J. (2019). [论文链接]
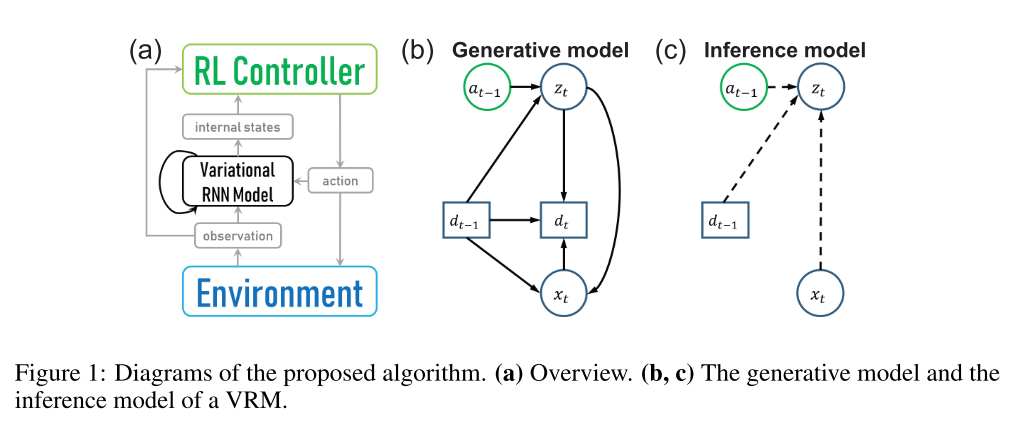
- 在部分可观察(PO)的环境中,深度强化学习(RL)智能体经常会表现出无法令人满意的性能,因为有两个问题需要一起解决:如何从原始观察中提取信息以解决任务,以及如何改进策略。在这项研究中,我们提出了用于解决PO任务的RL算法。我们的方法包括两部分:用于对环境建模的variational recurrent model(VRM),以及可以访问环境和VRM的RL控制器。所提出的算法在两种类型的PO机器人控制任务中进行了测试,包括坐标或速度均不可观察到,或者需要长期记忆的任务。我们的实验表明,在无法通过简单方式从原始观测值中推断未观测状态的任务中,所提出的算法比其他替代方法具有更高的数据效率和/或学习了更多的最佳策略。代码可以从这里获取到:https://github.com/oist-cnru/Variational-Recurrent-Models
POPULATION-GUIDED PARALLEL POLICY SEARCH FOR REINFORCEMENT LEARNING. Jung, W., Park, G., & Sung, Y. (2019). [论文链接]
- 在本文中,提出了一种新的population-guided的并行学习方案,以增强off-policy强化学习(RL)的性能。在提出的方案中,具有相同的value-function和策略的多个相同的学习器共享一个共同的经验replay buffer,并在最佳策略信息的指导下协作搜索一个好的策略。关键是通过构建用于策略更新的增强损失函数以扩大多个学习器的整体搜索范围,从而以柔和的方式融合最佳策略的信息。先前最佳策略的指导和扩大的范围可以更快,更好地搜索策略。理论上证明了所提方案对预期累积收益的单调改善。通过将提出的方案应用于twin delayed deep deterministic(TD3)策略梯度算法来构造当前算法。数值结果表明,所构造的算法优于大多数当前最新的RL算法,并且在稀疏的奖励环境下,收益非常可观。
Q-LEARNING WITH UCB EXPLORATION IS SAMPLE EFFICIENT FOR INFINITE-HORIZON MDP. Dong, K., Wang, Y., Chen, X., & Wang, L. (2019). [论文链接]
- 强化学习中的一个基本问题是,无模型算法是否有效。 最近,Jin等。 (2018)提出了一种基于UCB探索策略的Q学习算法,并证明了它对于有限水平的情节式MDP具有几乎最佳的后悔约束。 在本文中,我们在不访问生成模型的情况下,将具有UCB探索奖金的Q学习应用于具有折扣奖励的无限水平MDP。 我们证明了我们算法探索的样本复杂度受〜O(SAα2(1-γ)7)。 在这种情况下,通过延迟Q学习(Strehl)可以达到〜O(SA?4(1-γ)8)的最佳结果。等(2006年),并根据?匹配下限。 以及S和A直至对数因子。
ACTION SEMANTICS NETWORK: CONSIDERING THE EFFECTS OF ACTIONS IN MULTIAGENT SYSTEMS. Wang, W., Yang, T., Liu, Y., Hao, J., Hao, X., Hu, Y., … Gao, Y. (2019). [论文链接]
- 在多智能体系统(MASs)中,每个智能体都做出各自的决定,但是它们全都对系统演化做出了全局贡献。在MASs中学习很困难,因为每个智能体的行动选择必须在其他共同学习的智能体在场的情况下进行。此外,环境随机性和不确定性随着智能体数量的增加而呈指数增长。先前的工作将各种多智能体协调机制借鉴到深度学习架构中,以促进多智能体协调。但是,它们都不明确考虑智能体之间动作的语义,即不同的动作对其他智能体的影响不同。在本文中,我们提出了一种新的网络体系结构,称为动作语义网络(ASN),可以明确表示智能体之间的这种动作语义。 ASN使用基于它们之间动作语义的神经网络来表征不同动作对其他智能体的影响。ASN可以轻松地与现有的深度强化学习(DRL)算法结合使用,以提高其性能。在StarCraft II micromanagement和Neural MMO上的实验结果表明,与几种网络体系结构相比,ASN可以显着提高最新DRL方法的性能。
VID2GAME: CONTROLLABLE CHARACTERS EX-TRACTED FROM REAL-WORLD VIDEOS. Gafni, O., Wolf, L., & Taigman, Y. (2019). [论文链接]
- 我们从执行某项活动的人的视频中提取可控模型。 该模型根据用户定义的控制信号生成该人的新颖图像序列,该信号通常会标记移动物体的位移。 生成的视频可以具有任意背景,并且可以有效地捕获人的动态和外观。 该方法基于两个网络。 第一个将当前姿势和单实例控制信号映射到下一个姿势。 第二个将当前姿势,新姿势和给定的背景映射到输出帧。 这两个网络都包含实现高质量性能的多种新颖性。 从舞者和运动员的各种视频中提取的多个角色可以证明这一点。
1个
- 我们从执行某项活动的人的视频中提取可控模型。 该模型根据用户定义的控制信号生成该人的新颖图像序列,该信号通常会标记移动物体的位移。 生成的视频可以具有任意背景,并且可以有效地捕获人的动态和外观。 该方法基于两个网络。 第一个将当前姿势和单实例控制信号映射到下一个姿势。 第二个将当前姿势,新姿势和给定的背景映射到输出帧。 这两个网络都包含实现高质量性能的多种新颖性。 从舞者和运动员的各种视频中提取的多个角色可以证明这一点。
Optimistic Exploration even with a Pessimistic Initialisation. Rashid, T., Peng, B., Böhmer, W., & Whiteson, S. (2020). [论文链接]
- 乐观初始化是在强化学习(RL)中进行有效探索的有效策略。在表格形式的情况下,所有可证明有效的无模型算法都依赖于它。然而,尽管从这些可证明有效的表格算法中获得了启发,但无模型的深度RL算法并未使用乐观初始化。特别地,在仅具有正回报的情况下,由于常用的网络初始化方案(悲观的初始化),Q值被初始化为它们的最低可能值。仅初始化网络以输出乐观的Q值是不够的,因为我们不能确保它们对于新颖的状态-动作对保持乐观,这对探索至关重要。我们提出了一个简单的基于计数的增值,以悲观地初始化Q值,从而将乐观的来源与神经网络分开。我们证明了该方案在表格设置中可证明是有效的,并将其扩展到深度RL设置。我们的算法,乐观悲观初始化的Q学习(OPIQ),使用基于计数的奖金来增加基于DQN的代理的Q值估计,以确保在操作选择和自举过程中保持乐观。我们显示,OPIQ优于非乐观DQN变体,这些变体在艰苦的探索任务中利用了基于伪计数的内在动机,并且预测了新型状态作用对的乐观估计。
1个
- 乐观初始化是在强化学习(RL)中进行有效探索的有效策略。在表格形式的情况下,所有可证明有效的无模型算法都依赖于它。然而,尽管从这些可证明有效的表格算法中获得了启发,但无模型的深度RL算法并未使用乐观初始化。特别地,在仅具有正回报的情况下,由于常用的网络初始化方案(悲观的初始化),Q值被初始化为它们的最低可能值。仅初始化网络以输出乐观的Q值是不够的,因为我们不能确保它们对于新颖的状态-动作对保持乐观,这对探索至关重要。我们提出了一个简单的基于计数的增值,以悲观地初始化Q值,从而将乐观的来源与神经网络分开。我们证明了该方案在表格设置中可证明是有效的,并将其扩展到深度RL设置。我们的算法,乐观悲观初始化的Q学习(OPIQ),使用基于计数的奖金来增加基于DQN的代理的Q值估计,以确保在操作选择和自举过程中保持乐观。我们显示,OPIQ优于非乐观DQN变体,这些变体在艰苦的探索任务中利用了基于伪计数的内在动机,并且预测了新型状态作用对的乐观估计。
FINDING AND VISUALIZING WEAKNESSES OF DEEP REINFORCEMENT LEARNING AGENTS. Rupprecht, C., Ibrahim, C., & Pal, C. J. (2019). [论文链接]
- 随着视觉感知驱动的深度强化学习变得越来越广泛,人们越来越需要更好地理解和探究所学习的主体。 了解决策过程及其与视觉输入的关系对于识别学习行为中的问题非常有价值。 但是,这个话题在研究界相对未被充分研究。 在这项工作中,我们提出了一种为受过训练的特工合成感兴趣的视觉输入的方法。 这样的输入或状态可能是需要采取特定行动的情况。 此外,能够获得非常高或非常低的报酬的临界状态通常对于理解系统的态势感知很有趣,因为它们可以对应于危险状态。 为此,我们学习了环境状态空间上的生成模型,并使用其潜在空间来优化目标状态的目标函数。 在我们的实验中,我们证明了这种方法可以为各种环境和强化学习方法提供见解。 我们在标准Atari基准游戏以及自动驾驶模拟器中探索结果。 基于我们使用这种技术能够识别行为缺陷的效率,我们相信这种通用方法可以作为AI安全应用程序的重要工具。
1个
- 随着视觉感知驱动的深度强化学习变得越来越广泛,人们越来越需要更好地理解和探究所学习的主体。 了解决策过程及其与视觉输入的关系对于识别学习行为中的问题非常有价值。 但是,这个话题在研究界相对未被充分研究。 在这项工作中,我们提出了一种为受过训练的特工合成感兴趣的视觉输入的方法。 这样的输入或状态可能是需要采取特定行动的情况。 此外,能够获得非常高或非常低的报酬的临界状态通常对于理解系统的态势感知很有趣,因为它们可以对应于危险状态。 为此,我们学习了环境状态空间上的生成模型,并使用其潜在空间来优化目标状态的目标函数。 在我们的实验中,我们证明了这种方法可以为各种环境和强化学习方法提供见解。 我们在标准Atari基准游戏以及自动驾驶模拟器中探索结果。 基于我们使用这种技术能够识别行为缺陷的效率,我们相信这种通用方法可以作为AI安全应用程序的重要工具。
ACTOR-CRITIC PROVABLY FINDS NASH EQUILIBRIA OF LINEAR-QUADRATIC MEAN-FIELD GAMES. Fu, Z., Yang, Z., Chen, Y., & Wang, Z. (2019). [论文链接]
- 我们研究了具有无限数量座席的离散时间均值马尔可夫博弈,其中每个座席旨在使遍历成本最小化。 我们考虑这样的设置:代理具有相同的线性状态转换和二次成本函数,而代理的聚集效应则由其状态的总体平均值即均值场状态来捕获。 对于这种博弈,基于纳什确定性等价原理,我们为其纳什均衡的存在和唯一性提供了充分的条件。 此外,为了找到Nash平衡,我们提出了一种具有线性函数近似的均值actor-critic算法,该算法不需要了解动力学模型。 具体来说,在我们算法的每次迭代中,我们都使用单主体参与者评判算法在给定当前平均场状态的情况下大致获得每个主体的最优策略,然后更新平均场状态。 特别地,我们证明了我们的算法以线性速率收敛到Nash平衡。 据我们所知,这是将具有函数逼近的无模型强化学习应用于具有可证明的非渐近全局收敛性保证的离散时间均值马尔可夫博弈的第一个成功。
Option Discovery using Deep Skill Chaining. Bagaria, A., & Konidaris, G. (2020). ICLR. [论文链接]
- 自动发现时间上可扩展的动作或技能是分层强化学习的长期目标。我们提出了一种新的算法,该算法将技能链与深度神经网络相结合,可以在高维、连续域中自动发现技能。最终的算法,即deep skill chaining,通过这样的属性来构建技能,即当执行一个时使能智能体去执行另一个。(constructs skills with the property that executing one enables the agent to execute another.) 我们证明,在挑战性的连续控制任务中,deep skill chaining显着优于非分层智能体和其他最新的技能发现技术。
Dynamical Distance Learning for Semi-Supervised and Unsupervised Skill Discovery. Hartikainen, K., Geng, X., Haarnoja, T., & Levine, S. (2019). [论文链接]
- 强化学习需要手动指定奖励函数才能学习任务。虽然原则上该奖励函数仅需要指定任务目标,但在实践中,强化学习可能非常耗时甚至不可行,除非对奖励函数进行了调整,以便产生平滑的梯度导向成功的结果。但手动调整是很难的,尤其是从原始观察结果(例如图像)获取任务时。在本文中,我们研究了如何自动学习动态距离:一种从任何其他状态到达给定目标状态的预期时间步个数的度量。这些动态距离可用于提供well-shaped奖励函数,以实现新的目标,从而有可能有效地学习复杂的任务。我们表明动态距离可以被用于半监督,其中无监督与环境的交互用于学习动态距离,而少量的偏好监督用于确定任务目标,而无需任何人工设计的奖励函数或目标示例。我们在真实机器人和仿真中都评估了我们的方法。我们展示了我们的方法可以使用原始的9自由度机械手学习阀门的转动,使用原始图像观察结果和十个偏好标签,而无需任何其他监督。
IMITATION LEARNING VIA OFF-POLICY DISTRIBUTION MATCHING. Kostrikov, I., Nachum, O., Tompson, J., & Research, G. (2019). IMITATION LEARNING VIA OFF-POLICY DISTRIBUTION MATCHING. [论文链接]
- 当从专家演示中进行模仿学习时,分布匹配是一种流行的方法,其中一种是在估计分配比率之间交替,然后在标准强化学习(RL)算法中将这些比率用作奖励。 传统上,分配比率的估计需要策略数据,这导致先前的工作要么数据效率过高,要么以能够极大地改变其最佳目标的方式更改原始目标。 在这项工作中,我们展示了如何以一种有原则的方式将原始分配比率估算目标转化为完全脱离政策的目标。 除了提供的数据效率外,我们还可以证明该目标也使得无需使用单独的RL优化。 而是,可以从该目标直接学习模仿策略,而无需使用明确的奖励。 我们将得到的算法称为ValueDICE,并在一套流行的模仿学习基准上对其进行评估,发现它可以实现最新的样本效率和性能。11
CAQL: CONTINUOUS ACTION Q-LEARNING. Ryu, M., Chow, Y., Anderson, R., Tjandraatmadja, C., Boutilier, C., & Research, G. (2019). CAQL: CONTINUOUS ACTION Q-LEARNING.[论文链接]
- 基于价值的强化学习(RL)方法(例如Q学习)已在多个领域取得成功。 然而,将Q学习应用于连续动作RL问题的一个挑战是最佳Bellman备份所需的连续动作最大化(max-Q)。 在这项工作中,我们开发了CAQL,这是一种用于连续动作Q学习的算法(类),可以使用多个即插即用优化器来解决max-Q问题。 利用最新的深度神经网络优化结果,我们表明可以使用混合整数编程(MIP)来最佳解决max-Q问题。 当Q函数表示具有足够的功效时,基于MIP的优化会产生更好的策略,并且比近似方法(例如梯度上升,交叉熵搜索)更健壮。 我们进一步开发了几种技术来加速CAQL中的推理,尽管它们具有近似性质,但它们的性能很好。 我们将CAQL与具有不同动作约束度的基准连续控制问题上最先进的RL算法进行比较,结果表明,CAQL在严重受限的环境中通常优于基于策略的方法。
1个
- 基于价值的强化学习(RL)方法(例如Q学习)已在多个领域取得成功。 然而,将Q学习应用于连续动作RL问题的一个挑战是最佳Bellman备份所需的连续动作最大化(max-Q)。 在这项工作中,我们开发了CAQL,这是一种用于连续动作Q学习的算法(类),可以使用多个即插即用优化器来解决max-Q问题。 利用最新的深度神经网络优化结果,我们表明可以使用混合整数编程(MIP)来最佳解决max-Q问题。 当Q函数表示具有足够的功效时,基于MIP的优化会产生更好的策略,并且比近似方法(例如梯度上升,交叉熵搜索)更健壮。 我们进一步开发了几种技术来加速CAQL中的推理,尽管它们具有近似性质,但它们的性能很好。 我们将CAQL与具有不同动作约束度的基准连续控制问题上最先进的RL算法进行比较,结果表明,CAQL在严重受限的环境中通常优于基于策略的方法。
AMRL: AGGREGATED MEMORY FOR REINFORCEMENT LEARNING. Beck, J., Ciosek, K., Devlin, S., Tschiatschek, S., Zhang, C., & Hofmann, K. (2019). [论文链接]
- 在许多部分可观察的方案中,强化学习(RL)代理必须依靠长期记忆才能学习最佳策略。 我们证明,由于来自环境和探索的随机性,使用自然语言处理和监督学习的技术在RL任务中失败了。 利用我们对RL中传统存储方法的局限性的见解,我们提出了AMRL,这是一类模型,可以学习更好的策略,具有更高的采样效率,并且对噪声输入具有弹性。 具体来说,我们的模型使用标准内存模块来总结短期上下文,然后从标准模型中汇总所有先前状态,而不考虑顺序。 我们表明,这提供了随时间变化的梯度衰减和信噪比方面的优势。 在测试长期记忆的Minecraft和迷宫环境中进行评估后,我们发现,与参数数量相同的基准相比,我们的模型将平均收益提高了19%,与参数更多的基准相比,将其平均收益提高了9%。
1个
- 在许多部分可观察的方案中,强化学习(RL)代理必须依靠长期记忆才能学习最佳策略。 我们证明,由于来自环境和探索的随机性,使用自然语言处理和监督学习的技术在RL任务中失败了。 利用我们对RL中传统存储方法的局限性的见解,我们提出了AMRL,这是一类模型,可以学习更好的策略,具有更高的采样效率,并且对噪声输入具有弹性。 具体来说,我们的模型使用标准内存模块来总结短期上下文,然后从标准模型中汇总所有先前状态,而不考虑顺序。 我们表明,这提供了随时间变化的梯度衰减和信噪比方面的优势。 在测试长期记忆的Minecraft和迷宫环境中进行评估后,我们发现,与参数数量相同的基准相比,我们的模型将平均收益提高了19%,与参数更多的基准相比,将其平均收益提高了9%。
DEEP IMITATIVE MODELS FOR FLEXIBLE INFERENCE, PLANNING, AND CONTROL. Rhinehart, N., Mcallister, R., & Levine, S. (2019). [论文链接]
- 模仿学习(IL)是学习理想的自主行为的一种吸引人的方法。 但是,指导IL实现任意目标是困难的。 相反,基于计划的算法使用动力学模型和奖励函数来实现目标。 然而,通常难以指定唤起期望行为的奖励功能。 在本文中,我们提出了“模仿模型”,以结合IL和目标导向计划的好处。 模仿模型是期望行为的概率预测模型,能够预测可解释的类似专家的轨迹以实现特定目标。 我们得出了一系列灵活的目标目标,包括受约束的目标区域,不受约束的目标集和基于能量的目标。 我们证明了我们的方法可以利用这些目标成功地指导行为。 在动态模拟自动驾驶任务中,我们的方法明显优于六个IL方法和基于计划的方法,并且可以从专家演示中高效学习而无需在线数据收集。 我们还展示了我们的方法对于未明确指定的目标(如道路错误一侧的目标)是可靠的。
CM3: Cooperative Multi-goal Multi-stage Multi-agent Reinforcement Learning. Yang, J., Nakhaei, A., Isele, D., Fujimura, K., & Zha, H. (2018). [论文链接]
- 多种协作式多主体控制问题要求主体在实现集体成功的同时实现个人目标。 这种多目标的多主体设置为最近的算法带来了困难,这些算法主要针对具有单一全局奖励的设置,这归因于两个新的挑战:有效地探索学习个人目标达成和合作以他人的成功,以及为他人分配成功的学分 不同代理商的行动与目标之间的互动。 为了解决这两个挑战,我们将问题重构为一个新颖的两阶段课程,其中在学习多人合作之前先学习单人目标达成,然后得出一个新的多目标多人政策梯度。 用于本地化信用分配的信用函数。 我们使用功能增强方案来桥接整个课程的价值和政策功能。 完整的架构称为CM3,其在三种具有挑战性的多目标多主体问题上的学习速度远比现有算法的直接改编快:在困难编队中进行协作导航,在SUMO交通模拟器中协商多车道变更以及战略合作 在Checkers环境中。
1个
- 多种协作式多主体控制问题要求主体在实现集体成功的同时实现个人目标。 这种多目标的多主体设置为最近的算法带来了困难,这些算法主要针对具有单一全局奖励的设置,这归因于两个新的挑战:有效地探索学习个人目标达成和合作以他人的成功,以及为他人分配成功的学分 不同代理商的行动与目标之间的互动。 为了解决这两个挑战,我们将问题重构为一个新颖的两阶段课程,其中在学习多人合作之前先学习单人目标达成,然后得出一个新的多目标多人政策梯度。 用于本地化信用分配的信用函数。 我们使用功能增强方案来桥接整个课程的价值和政策功能。 完整的架构称为CM3,其在三种具有挑战性的多目标多主体问题上的学习速度远比现有算法的直接改编快:在困难编队中进行协作导航,在SUMO交通模拟器中协商多车道变更以及战略合作 在Checkers环境中。
Intrinsic Motivation for Encouraging Synergistic Behavior. Chitnis, R., Tulsiani, S., Gupta, S., & Gupta, A. (2020). [论文链接]
- 我们研究内在驱动在稀疏奖励协同任务中作为强化学习探索bias的作用,这些任务是多个智能体必须共同努力才能实现他们无法单独实现的目标的任务。我们的核心思想是,协同任务内在驱动的一个好的指导原则是,采取那些如果智能体自己行动,就无法实现的影响世界的行动。因此,我们建议激励智能体采取(联合)行动,这些行动的效果无法通过每个单独智能体的预测组合来预测。我们研究了这种想法的两种实例,一种基于遇到的真实状态,另一种基于与策略同时训练的动力学模型。尽管前者较为简单,但后者的好处是对采取的动作可微。我们在奖励稀疏的机器人双臂操作和多智能体移动任务中验证了我们的方法。我们发现,与以下两种方法相比,我们的方法产生的效率更高:1)仅使用稀疏奖励进行训练; 2)使用surprise-based的典型内在驱动形式,而这种形式并不偏向于协同行为。视频可在项目网页上找到:https://sites.google.com/view/iclr2020-synergistic。
GRAPH CONSTRAINED REINFORCEMENT LEARNING FOR NATURAL LANGUAGE ACTION SPACES. Ammanabrolu, P., & Hausknecht, M. (2019). [论文链接]
- 交互式小说游戏是基于文本的模拟,其中,代理人完全通过自然语言与世界互动。 它们是研究如何扩展强化学习代理来满足自然语言理解,部分可观察性以及组合大的基于文本的动作空间中的动作生成等挑战的理想环境。 我们介绍了KG-A2C1,它是一种在基于模板的动作空间中探索并生成动作的同时构建动态知识图的代理。 我们认为,知识图的双重使用来推理游戏状态并限制自然语言的生成是组合性大自然语言动作的可扩展探索的关键。 各种IF游戏的结果表明,尽管动作空间大小呈指数增长,但KG-A2C的表现仍优于目前的IF代理。
1个
- 交互式小说游戏是基于文本的模拟,其中,代理人完全通过自然语言与世界互动。 它们是研究如何扩展强化学习代理来满足自然语言理解,部分可观察性以及组合大的基于文本的动作空间中的动作生成等挑战的理想环境。 我们介绍了KG-A2C1,它是一种在基于模板的动作空间中探索并生成动作的同时构建动态知识图的代理。 我们认为,知识图的双重使用来推理游戏状态并限制自然语言的生成是组合性大自然语言动作的可扩展探索的关键。 各种IF游戏的结果表明,尽管动作空间大小呈指数增长,但KG-A2C的表现仍优于目前的IF代理。
COMPOSING TASK-AGNOSTIC POLICIES WITH DEEP REINFORCEMENT LEARNING. Qureshi, A. H., Johnson, J. J., Qin, Y., Henderson, T., Boots, B., & Yip, M. C. (2019). [论文链接]
- 用基本行为的构成去解决迁移学习难题的是构建人工智能的关键要素之一。迄今为止,在学习task-specific的策略或技能方面已经有了大量工作,但几乎没有关注构建与任务无关的必要技能以找到新问题的解决方案。在本文中,我们提出了一种新的,基于深度强化学习的技能迁移和组合方法,该方法采用智能体的primitive策略来解决未曾见过的任务。我们在困难的环境中评估我们的方法,在这些环境中,通过标准强化学习(RL)甚至是分层RL的训练策略要么不可行,要么表现出较高的样本复杂性。我们证明了我们的方法不仅可以将技能迁移到新的问题设置中,而且还可以解决既需要任务计划又需要运动控制的挑战性环境,且数据效率很高。
Discovering Motor Programs By Recomposing Demonstrations. Excellence, P. D. (2020). 1–21. [论文链接]
- 在本文中,我们提出了一种从大规模且多样化的操作演示中来学习可重构motor primitives的方法。当前将演示分解为primitives的方法通常采用手动定义的primitives,而绕开了发现这些primitives的难度。另一方面,用于发现primitives的方法对primitive的复杂性进行了限制性假设,这使得任务的适用性限制在了狭窄的范围。我们的方法试图通过同时学习基础的motor primitives并重组这些primitives以重构原始演示来应对这些挑战。通过限制primitives分解的简约性和给定primitive的简单性,我们能够学习各种不同的motor primitives,以及它们的连贯潜在表示。我们从定性和定量两个方面证明了我们所学的primitives捕获了演示中语义上有意义的方面。这使我们能够在分层强化学习设置中组合这些primitives,以有效解决机器人操作任务,例如伸手和推手。
JELLY BEAN WORLD: A TESTBED FOR NEVER-ENDING LEARNING. Platanios, E. A., Saparov, A., & Mitchell, T. (2019). [论文链接]
- 机器学习近年来已显示出越来越大的成功。但是,当前的机器学习系统高度专业化,经过特定问题或领域的培训,通常在单个狭窄的数据集上进行培训。另一方面,人类学习具有高度的通用性和适应性。永无止境的学习是一种旨在弥合这一鸿沟的机器学习范例,其目的是鼓励研究人员设计能够学习在更复杂的环境中执行各种相互关联的任务的机器学习系统。迄今为止,还没有任何环境或测试平台可以促进永无止境的学习系统的开发和评估。为此,我们提出了Jelly Bean World测试平台。 “果冻豆世界”允许您在二维网格世界中进行实验,该世界充满了物品并且代理可以在其中导航。该测试平台提供了足够复杂的环境,并且在一般情况下,智能算法应比当前最新的强化学习方法具有更好的性能。它通过产生非平稳环境并促进多任务,多代理,多模式和课程学习设置的实验来实现。我们希望,“果冻豆世界”将激发人们对永无止境的学习以及更广泛的通用情报发展的新兴趣。
1个
- 机器学习近年来已显示出越来越大的成功。但是,当前的机器学习系统高度专业化,经过特定问题或领域的培训,通常在单个狭窄的数据集上进行培训。另一方面,人类学习具有高度的通用性和适应性。永无止境的学习是一种旨在弥合这一鸿沟的机器学习范例,其目的是鼓励研究人员设计能够学习在更复杂的环境中执行各种相互关联的任务的机器学习系统。迄今为止,还没有任何环境或测试平台可以促进永无止境的学习系统的开发和评估。为此,我们提出了Jelly Bean World测试平台。 “果冻豆世界”允许您在二维网格世界中进行实验,该世界充满了物品并且代理可以在其中导航。该测试平台提供了足够复杂的环境,并且在一般情况下,智能算法应比当前最新的强化学习方法具有更好的性能。它通过产生非平稳环境并促进多任务,多代理,多模式和课程学习设置的实验来实现。我们希望,“果冻豆世界”将激发人们对永无止境的学习以及更广泛的通用情报发展的新兴趣。
Single Episode Policy Transfer in Reinforcement Learning. Yang, J., Petersen, B., Zha, H., & Faissol, D. (2019). [论文链接]
- 转移和适应新的未知环境动态是强化学习(RL)的关键挑战。更大的挑战是在测试时间的一次尝试中可能几乎无法达到最佳效果,而可能无法获得丰厚的回报,而当前的方法却无法解决这一问题,而当前的方法需要多次使用经验来进行适应。为了在具有相关动力学的环境系列中实现单集传输,我们提出了一种通用算法,该算法可优化探测器和推理模型,以快速估算测试动力学的潜在潜变量,然后将其立即用作通用控制策略的输入。这种模块化的方法可以集成最新的算法以用于变化推理或RL。此外,我们的方法不需要在测试时获得奖励,因此可以在现有的自适应方法无法执行的环境中执行。在具有单个情节测试约束的不同实验领域中,我们的方法明显优于现有的自适应方法,并且相对于可靠的传输性能,在基线方面显示出良好的性能。
1个
- 转移和适应新的未知环境动态是强化学习(RL)的关键挑战。更大的挑战是在测试时间的一次尝试中可能几乎无法达到最佳效果,而可能无法获得丰厚的回报,而当前的方法却无法解决这一问题,而当前的方法需要多次使用经验来进行适应。为了在具有相关动力学的环境系列中实现单集传输,我们提出了一种通用算法,该算法可优化探测器和推理模型,以快速估算测试动力学的潜在潜变量,然后将其立即用作通用控制策略的输入。这种模块化的方法可以集成最新的算法以用于变化推理或RL。此外,我们的方法不需要在测试时获得奖励,因此可以在现有的自适应方法无法执行的环境中执行。在具有单个情节测试约束的不同实验领域中,我们的方法明显优于现有的自适应方法,并且相对于可靠的传输性能,在基线方面显示出良好的性能。
MODEL-AUGMENTED ACTOR-CRITIC: BACKPROPAGATING THROUGH PATHS. Clavera, I., Fu, Y., & Abbeel, P. (2019). [论文链接]
- 当前基于模型的强化学习方法只是将模型用作学习的黑匣子模拟器,以扩充数据以进行策略优化或价值函数学习。在本文中,我们展示了如何通过利用模型的可区分性来更有效地利用该模型。我们构建了一个策略优化算法,该算法在未来的时间范围内使用学习的模型和策略的路径派生方法。通过使用终极价值函数,以行为者批判的方式学习策略,可以防止跨多个时间步骤学习的不稳定性。此外,我们根据模型和值函数中的梯度误差提出了对我们目标的单调改进的推导。我们证明,我们的方法(i)始终比现有的基于模型的现有算法效率更高;(ii)匹配无模型算法的渐近性能;(iii)可以扩展到很长一段时间,通常过去的基于模型的方法都难以解决的问题。
1个
- 当前基于模型的强化学习方法只是将模型用作学习的黑匣子模拟器,以扩充数据以进行策略优化或价值函数学习。在本文中,我们展示了如何通过利用模型的可区分性来更有效地利用该模型。我们构建了一个策略优化算法,该算法在未来的时间范围内使用学习的模型和策略的路径派生方法。通过使用终极价值函数,以行为者批判的方式学习策略,可以防止跨多个时间步骤学习的不稳定性。此外,我们根据模型和值函数中的梯度误差提出了对我们目标的单调改进的推导。我们证明,我们的方法(i)始终比现有的基于模型的现有算法效率更高;(ii)匹配无模型算法的渐近性能;(iii)可以扩展到很长一段时间,通常过去的基于模型的方法都难以解决的问题。
Synthesizing Programmatic Policies that Inductively Generalize. Jeevana Priya Inala, Osbert Bastani, Zenna Tavares, A. S.-L. (2019). [论文链接]
- 深度强化学习已成功解决了许多具有挑战性的控制任务。 但是,学到的策略通常很难推广到新颖的环境。 我们提出了一种用于学习可捕获重复行为的程序化状态机策略的算法。 这样一来,他们便具有将泛化到需要任意重复次数的实例的能力,我们称其为归纳泛化。 但是,状态机策略由连续结构和离散结构组成,因此很难学习。 我们提出了一种称为自适应教学的学习框架,该框架通过模仿老师来学习状态机策略。 与传统的模仿学习相反,我们的老师根据学生的结构来自适应地自我更新。 我们展示了如何使用我们的算法来学习归纳推广到新型环境的策略,而传统的神经网络策略却无法做到。
1个
- 深度强化学习已成功解决了许多具有挑战性的控制任务。 但是,学到的策略通常很难推广到新颖的环境。 我们提出了一种用于学习可捕获重复行为的程序化状态机策略的算法。 这样一来,他们便具有将泛化到需要任意重复次数的实例的能力,我们称其为归纳泛化。 但是,状态机策略由连续结构和离散结构组成,因此很难学习。 我们提出了一种称为自适应教学的学习框架,该框架通过模仿老师来学习状态机策略。 与传统的模仿学习相反,我们的老师根据学生的结构来自适应地自我更新。 我们展示了如何使用我们的算法来学习归纳推广到新型环境的策略,而传统的神经网络策略却无法做到。
Robust Reinforcement Learning for Continuous Control with Model Misspecification. Mankowitz, D. J., Levine, N., Jeong, R., Shi, Y., Kay, J., Abdolmaleki, A., … Riedmiller, M. (2019). [论文链接]
- 我们提供了一个框架,可将鲁棒性(过渡动态中的扰动,我们称为模型错误指定)纳入连续控制强化学习(RL)算法中。我们特别专注于将鲁棒性整合到最新的连续控制RL算法中,该算法称为最大后验策略优化(MPO)。我们通过学习针对最坏情况的预期回报目标进行优化并得出相应的鲁棒熵正则化Bellman压缩算子的策略来实现这一目标。此外,我们引入了一个相对保守,软鲁棒,熵调节的物镜,并带有相应的Bellman算子。我们显示,在环境扰动下,健壮和软健政策在9个Mujoco域中的性能均优于非健壮政策。此外,我们在高维,模拟,灵巧的机器人手上显示出改进的鲁棒性能。最后,我们提出了多个调查性实验,这些实验提供了对鲁棒性框架的更深入了解。这包括对另一种连续控制RL算法的适应,以及从离线数据中学习不确定性集。可以在https://sites.google.com/view/robust-rl上在线找到表演视频。
FREQUENCY-BASED SEARCH-CONTROL IN DYNA. Pan, Y., Mei, J., & Farahmand, A.-M. (2019). [论文链接]
- 基于模型的强化学习已通过经验证明是提高样本效率的成功策略。特别地,Dyna是一个优雅的基于模型的体系结构,将学习和计划结合在一起,为使用模型提供了极大的灵活性。 Dyna中最重要的组件之一称为搜索控制,它是指生成状态或状态-动作对的过程,我们从中查询模型以获取模拟体验。搜索控制对于提高学习效率至关重要。在这项工作中,我们通过搜索值函数的高频区域,提出了一种简单而新颖的搜索控制策略。我们的主要直觉是基于信号处理的香农采样定理,这表明高频信号需要更多的样本来进行重构。我们凭经验表明,高频函数很难近似。这建议了一种搜索控制策略:我们应该使用值函数高频区域的状态来查询模型以获取更多样本。我们开发了一种简单的策略,可以通过梯度和粗麻布范数局部测量函数的频率,并为该方法提供理论依据。然后,我们将我们的策略应用于Dyna中的搜索控制,并进行实验以显示其在基准域上的性质和有效性。
1个
- 基于模型的强化学习已通过经验证明是提高样本效率的成功策略。特别地,Dyna是一个优雅的基于模型的体系结构,将学习和计划结合在一起,为使用模型提供了极大的灵活性。 Dyna中最重要的组件之一称为搜索控制,它是指生成状态或状态-动作对的过程,我们从中查询模型以获取模拟体验。搜索控制对于提高学习效率至关重要。在这项工作中,我们通过搜索值函数的高频区域,提出了一种简单而新颖的搜索控制策略。我们的主要直觉是基于信号处理的香农采样定理,这表明高频信号需要更多的样本来进行重构。我们凭经验表明,高频函数很难近似。这建议了一种搜索控制策略:我们应该使用值函数高频区域的状态来查询模型以获取更多样本。我们开发了一种简单的策略,可以通过梯度和粗麻布范数局部测量函数的频率,并为该方法提供理论依据。然后,我们将我们的策略应用于Dyna中的搜索控制,并进行实验以显示其在基准域上的性质和有效性。
Black-box Off-policy Estimation for Infinite-Horizon Reinforcement Learning. Ali Mousavi, Lihong Li, Qiang Liu, D. Z. (n.d.). [论文链接]
- 在许多现实生活中的应用(例如医疗保健和机器人技术)中,对长视距问题的非策略估计很重要,在这些应用中,可能无法使用高保真模拟器,而对策略的评估却非常昂贵或不可能。 最近,刘等。 (2018)提出了一种避免典型的基于重要性抽样的方法遭受地平线诅咒的方法。 尽管显示出令人鼓舞的结果,但这种方法在实践中受到限制,因为它需要从已知行为策略的固定分布中提取数据。 在这项工作中,我们提出了一种消除此类限制的新颖方法。 特别是,我们将问题公式化为解决某个运营商的固定点,并开发了一种新的估算器,该估算器可以计算平稳分布的重要性比,而无需知道如何收集非政策数据。 我们分析其渐近一致性和有限样本推广。 基准测试证明了该方法的有效性。
1个
- 在许多现实生活中的应用(例如医疗保健和机器人技术)中,对长视距问题的非策略估计很重要,在这些应用中,可能无法使用高保真模拟器,而对策略的评估却非常昂贵或不可能。 最近,刘等。 (2018)提出了一种避免典型的基于重要性抽样的方法遭受地平线诅咒的方法。 尽管显示出令人鼓舞的结果,但这种方法在实践中受到限制,因为它需要从已知行为策略的固定分布中提取数据。 在这项工作中,我们提出了一种消除此类限制的新颖方法。 特别是,我们将问题公式化为解决某个运营商的固定点,并开发了一种新的估算器,该估算器可以计算平稳分布的重要性比,而无需知道如何收集非政策数据。 我们分析其渐近一致性和有限样本推广。 基准测试证明了该方法的有效性。
MULTI-AGENT INTERACTIONS MODELING WITH CORRELATED POLICIES. Liu, M., Zhou, M., Zhang, W., Zhuang, Y., Wang, J., Liu, W., & Yu, Y. (2019). [论文链接]
- 上交, 华为
- 在多智能体系统中,由于主体之间的高关联性,导致了复杂的交互行为。但是,以前通过演示对多智能体交互建模的工作主要是通过假设策略及其奖励结构之间相互独立来进行约束的。本文将多智能体交互建模问题转化为一个多智能体模仿学习框架,该框架通过对对手策略的近似,对相关策略进行显式建模,从而恢复出能够重新生成相似交互的智能体策略。 因此,我们开发了Decentralized Adversarial Imitation Learning algorithm with Correlated policies(CoDAIL),该算法可进行去中心化的训练和执行。 各种实验表明,CoDAIL可以更好地重新生成复杂的与演示者相似的交互,并且胜过最新的多智能体模仿学习方法。 我们的代码可从https://github.com/apexrl/CoDAIL获得。
THINKING WHILE MOVING: DEEP REINFORCEMENT LEARNING WITH CONCURRENT CONTROL. Xiao, T., Jang, E., Kalashnikov, D., Levine, S., Ibarz, J., Hausman, K., … Berkeley, U. C. (2019). [论文链接]
- 我们在这样的环境中研究强化学习,即必须在受控系统的时间演变过程中同时从策略中采样一个动作,例如何时机器人必须在决定下一动作的同时仍执行前一个动作。就像人或动物一样,机器人必须同时思考和移动,在上一个动作完成之前决定下一个动作。为了开发用于此类并发控制问题的算法框架,我们从贝尔曼方程的连续时间公式开始,然后以了解系统延迟的方式离散化它们。通过对现有基于值的深度强化学习算法的简单体系结构扩展,我们实例化了此类新的近似动态编程方法。我们在模拟基准任务和大型机器人抓握任务(机器人必须“边走边思考”)上评估我们的方法。可以在https://sites.google.com/view/thinkingwhilemoving上获得视频。
1个
- 我们在这样的环境中研究强化学习,即必须在受控系统的时间演变过程中同时从策略中采样一个动作,例如何时机器人必须在决定下一动作的同时仍执行前一个动作。就像人或动物一样,机器人必须同时思考和移动,在上一个动作完成之前决定下一个动作。为了开发用于此类并发控制问题的算法框架,我们从贝尔曼方程的连续时间公式开始,然后以了解系统延迟的方式离散化它们。通过对现有基于值的深度强化学习算法的简单体系结构扩展,我们实例化了此类新的近似动态编程方法。我们在模拟基准任务和大型机器人抓握任务(机器人必须“边走边思考”)上评估我们的方法。可以在https://sites.google.com/view/thinkingwhilemoving上获得视频。
EVOLUTIONARY POPULATION CURRICULUM FOR SCALING MULTI-AGENT REINFORCEMENT LEARNING. Long, Q., Zhou, Z., Gupta, A., Fang, F., Wu, Y., & Wang, X. (2019). [论文链接]
- CMU, 上交
- 在多智能体游戏中,环境的复杂性会随着智能体数量的增加而呈指数增长,因此,当智能体数量众多时,学习良好的策略尤其具有挑战性。在本文中,我们介绍了Evolutionary Population Curriculum(EPC),这是一种课程学习范式,它通过逐步增加训练智能体的数量来扩大多智能体强化学习(MARL)的规模。此外,EPC使用进化方法来解决整个课程中的objective misalignment问题:在早期以少量成功训练的智能体不一定是适应数量规模较大的后期的最佳人选。具体而言,EPC在每个阶段维护多组智能体,对这些组执行混合匹配和微调,提拔最具适应性的智能体集合到下一阶段。我们在流行的MARL算法MADDPG上实现了EPC,并通过实验证明,随着智能体数量呈指数增长,我们的方法始终在性能上始终优于baselines。可以在https://sites.google.com/view/epciclr2020上找到源码和视频。
SAMPLE EFFICIENT POLICY GRADIENT METHODS WITH RECURSIVE VARIANCE REDUCTION. Xu, P., Gao, F., & Gu, Q. (2019). [论文链接]
- 在强化学习中提高样本效率一直是一个长期存在的研究问题。 在这项工作中,我们旨在降低现有策略梯度方法的样本复杂性。 我们提出了一种新的策略梯度算法,称为SRVR-PG,该算法仅需O(1 /?3/2)1次即可找到非凹面性能函数J(θ)的α-近似平稳点(即, 令?∇J(θ)?2 2≤?)。 该样本复杂度将随机方差减少策略梯度算法的现有结果O(1 /?5/3)提高了O(1 /?1/6)。 此外,我们还提出了带有参数探索功能的SRVR-PG的变体,它从先验概率分布中探索初始策略参数。 我们对强化学习中的经典控制问题进行了数值实验,以验证所提出算法的性能。
1个
- 在强化学习中提高样本效率一直是一个长期存在的研究问题。 在这项工作中,我们旨在降低现有策略梯度方法的样本复杂性。 我们提出了一种新的策略梯度算法,称为SRVR-PG,该算法仅需O(1 /?3/2)1次即可找到非凹面性能函数J(θ)的α-近似平稳点(即, 令?∇J(θ)?2 2≤?)。 该样本复杂度将随机方差减少策略梯度算法的现有结果O(1 /?5/3)提高了O(1 /?1/6)。 此外,我们还提出了带有参数探索功能的SRVR-PG的变体,它从先验概率分布中探索初始策略参数。 我们对强化学习中的经典控制问题进行了数值实验,以验证所提出算法的性能。
STATE-ONLY IMITATION WITH TRANSITION DYNAM-ICS MISMATCH. Gangwani, T., & Peng, J. (2019). [论文链接]
- 模仿学习(IL)是一种流行的范式,它用于培训代理人通过利用专家的行为来实现复杂的目标,而不是处理设计正确的奖励功能的困难。 在将环境建模为马尔可夫决策过程(MDP)的情况下,大多数现有的IL算法都依赖于与要学习新的模仿策略的MDP相同的MDP中的专家演示的可用性。 这在专家和模仿者MDP之间的差异很普遍的许多现实场景中并不常见,特别是在过渡动力学功能中。 此外,获得专家的行动可能代价高昂或不可行,这使得近来朝着仅基于状态的IL(专家演示仅构成状态或观察结果)的趋势大有希望。 在最近基于散度最小化思想的对抗模仿方法的基础上,本文提出了一种新的仅状态IL算法。 它通过引入间接步骤将总体优化目标分为两个子问题,并迭代地解决子问题。 我们表明,当专家和模仿者MDP之间的转换动力学不匹配时,我们的算法特别有效,而基准线IL方法会导致性能下降。 为了对此进行分析,我们通过修改来自OpenAI Gym 1的MuJoCo运动任务的配置参数来构造一些有趣的MDP。
1个
- 模仿学习(IL)是一种流行的范式,它用于培训代理人通过利用专家的行为来实现复杂的目标,而不是处理设计正确的奖励功能的困难。 在将环境建模为马尔可夫决策过程(MDP)的情况下,大多数现有的IL算法都依赖于与要学习新的模仿策略的MDP相同的MDP中的专家演示的可用性。 这在专家和模仿者MDP之间的差异很普遍的许多现实场景中并不常见,特别是在过渡动力学功能中。 此外,获得专家的行动可能代价高昂或不可行,这使得近来朝着仅基于状态的IL(专家演示仅构成状态或观察结果)的趋势大有希望。 在最近基于散度最小化思想的对抗模仿方法的基础上,本文提出了一种新的仅状态IL算法。 它通过引入间接步骤将总体优化目标分为两个子问题,并迭代地解决子问题。 我们表明,当专家和模仿者MDP之间的转换动力学不匹配时,我们的算法特别有效,而基准线IL方法会导致性能下降。 为了对此进行分析,我们通过修改来自OpenAI Gym 1的MuJoCo运动任务的配置参数来构造一些有趣的MDP。
Explain Your Move: Understanding Agent Actions Using Focused Feature Saliency. Gupta, P., Puri, N., Verma, S., Kayastha, D., Deshmukh, S., Krishnamurthy, B., & Singh, S. (2019). [论文链接]
- 随着深度强化学习(RL)应用于更多的任务,就需要形象化和了解所学特工的行为。 显着性图通过突出显示输入状态与代理采取行动最相关的特征来解释代理行为。 现有的基于扰动的计算显着性的方法通常会突出显示与代理采取的行动无关的输入区域。 我们的方法通过平衡两个方面(特异性和相关性)来生成更突出的显着性地图,这两个方面捕获了不同的显着期望。 第一个记录了摄动对将要解释的动作的相对预期回报的影响。 第二减重无关的功能改变了除了要说明的动作以外的动作的相对预期奖励。 我们将我们的方法与经过培训的可玩棋盘游戏(国际象棋和围棋)和Atari游戏(突破,Pong和太空侵略者)的代理商的现有方法进行比较。 通过示例性示例(Chess,Atari,Go),人体研究(Chess)和自动评估方法(Chess),我们的方法所产生的显着性图比现有方法对人类的解释性更高。
Network Randomization: A Simple Technique for Generalization in Deep Reinforcement Learning. Lee, K., Lee, K., Shin, J., & Lee, H. (2019). [论文链接]
- 深度强化学习(RL)主体通常无法推广到看不见的环境(但在语义上与受过训练的主体相似),尤其是当它们在高维状态空间(如图像)上受到训练时。 在本文中,我们提出了一种简单的技术,通过引入随机扰乱输入观测值的随机(卷积)神经网络来提高深层RL代理的泛化能力。 通过学习跨变化和随机环境不变的强大功能,它使受过训练的代理能够适应新的领域。 此外,我们考虑了一种基于蒙特卡洛近似的推理方法,以减少由该随机化引起的方差。 我们证明了我们的方法在2D CoinRun,3D DeepMind Lab探索和3D机器人控制任务中的优越性:在同一目的上,它明显优于各种正则化和数据增强方法。 可以在github.com/pokaxpoka/netrand上找到代码。
1个
- 深度强化学习(RL)主体通常无法推广到看不见的环境(但在语义上与受过训练的主体相似),尤其是当它们在高维状态空间(如图像)上受到训练时。 在本文中,我们提出了一种简单的技术,通过引入随机扰乱输入观测值的随机(卷积)神经网络来提高深层RL代理的泛化能力。 通过学习跨变化和随机环境不变的强大功能,它使受过训练的代理能够适应新的领域。 此外,我们考虑了一种基于蒙特卡洛近似的推理方法,以减少由该随机化引起的方差。 我们证明了我们的方法在2D CoinRun,3D DeepMind Lab探索和3D机器人控制任务中的优越性:在同一目的上,它明显优于各种正则化和数据增强方法。 可以在github.com/pokaxpoka/netrand上找到代码。
RIDE: REWARDING IMPACT-DRIVEN EXPLORATION FOR PROCEDURALLY-GENERATED ENVIRONMENTS. Raileanu, R., & Rocktäschel, T. (2019). [论文链接]
- 在稀疏奖励环境中进行探索仍然是无模型强化学习的主要挑战之一。 许多最先进的方法不仅仅依赖于环境提供的外部奖励,而是使用内在奖励来鼓励探索。 但是,我们表明,现有方法在程序生成的环境中不起作用,在该环境中,代理不可能多次访问某个状态。 我们提出了一种新型的内在奖励,这种内在奖励会鼓励代理采取行动,从而导致其学习状态表示形式发生重大变化。 我们在MiniGrid中对多个具有挑战性的程序生成的任务以及先前工作中使用的具有高维观察力的任务上评估我们的方法。 我们的实验表明,这种方法比现有的探索方法更有效,尤其是在程序生成的MiniGrid环境中。 此外,我们还分析了代理商的学习行为以及内在报酬。 与以前的方法相比,我们的内在报酬在训练过程中不会减少,并且由于与它可以控制的对象进行交互,它会大大奖励代理商。
1个
- 在稀疏奖励环境中进行探索仍然是无模型强化学习的主要挑战之一。 许多最先进的方法不仅仅依赖于环境提供的外部奖励,而是使用内在奖励来鼓励探索。 但是,我们表明,现有方法在程序生成的环境中不起作用,在该环境中,代理不可能多次访问某个状态。 我们提出了一种新型的内在奖励,这种内在奖励会鼓励代理采取行动,从而导致其学习状态表示形式发生重大变化。 我们在MiniGrid中对多个具有挑战性的程序生成的任务以及先前工作中使用的具有高维观察力的任务上评估我们的方法。 我们的实验表明,这种方法比现有的探索方法更有效,尤其是在程序生成的MiniGrid环境中。 此外,我们还分析了代理商的学习行为以及内在报酬。 与以前的方法相比,我们的内在报酬在训练过程中不会减少,并且由于与它可以控制的对象进行交互,它会大大奖励代理商。
PROJECTION-BASED CONSTRAINED POLICY OPTIMIZATION. Yang, T.-Y., Rosca, J., Narasimhan, K., & Ramadge, P. J. (2019). [论文链接]
- 我们考虑了学习控制策略的问题,该策略优化了奖励功能,同时又出于安全性,公平性或其他成本的考虑而满足约束条件。 我们提出了一种新算法,即基于投影的约束策略优化(PCPO)。 这是一种通过两步过程优化策略的迭代方法:第一步执行本地奖励改进更新,而第二步通过将策略投影回约束集来解决任何约束违规问题。 我们从理论上分析PCPO,并为每次策略更新提供了奖励改进的下限和约束违反的上限。 我们基于两个不同的指标进一步描述了PCPO的收敛性:L2范数和Kullback-Leibler差异。 我们在几个控制任务上的经验结果表明,与最先进的方法相比,PCPO的性能更高,约束违规平均减少3.5倍以上,回报提高约15%。11
COMBINING Q-LEARNING AND SEARCH WITH AMORTIZED VALUE ESTIMATES. Hamrick DeepMind, J. B., Bapst DeepMind, V., Sanchez-Gonzalez DeepMind, A., Pfaff DeepMind, T., Weber DeepMind, T., Buesing DeepMind, L., & Battaglia DeepMind, P. W. (2019). [论文链接]
- 我们介绍了“使用摊销价值估计进行搜索”(SAVE),一种将无模型Q学习与基于模型的蒙特卡洛树搜索(MCTS)相结合的方法。 在SAVE中,学习的先于状态操作值用于指导MCTS,MCTS估计状态操作值的改进集合。 然后将新的Q估计值与实际经验结合使用以更新先验值。 这有效地摊销了MCTS进行的价值计算,从而导致了无模型学习与基于模型的搜索之间的合作关系。 SAVE可以在任何具有模型访问权限的Q学习代理上实现,我们通过将其合并到执行具有挑战性的物理推理任务和Atari的代理中来进行演示。 与典型的基于模型的搜索方法相比,SAVE始终以较少的培训步骤来获得更高的回报,并且以很小的搜索预算即可获得出色的性能。 通过将实际经验与搜索过程中计算出的信息相结合,SAVE证明了可以同时提高无模型学习的性能和计划的计算成本。
1个
- 我们介绍了“使用摊销价值估计进行搜索”(SAVE),一种将无模型Q学习与基于模型的蒙特卡洛树搜索(MCTS)相结合的方法。 在SAVE中,学习的先于状态操作值用于指导MCTS,MCTS估计状态操作值的改进集合。 然后将新的Q估计值与实际经验结合使用以更新先验值。 这有效地摊销了MCTS进行的价值计算,从而导致了无模型学习与基于模型的搜索之间的合作关系。 SAVE可以在任何具有模型访问权限的Q学习代理上实现,我们通过将其合并到执行具有挑战性的物理推理任务和Atari的代理中来进行演示。 与典型的基于模型的搜索方法相比,SAVE始终以较少的培训步骤来获得更高的回报,并且以很小的搜索预算即可获得出色的性能。 通过将实际经验与搜索过程中计算出的信息相结合,SAVE证明了可以同时提高无模型学习的性能和计划的计算成本。
TOWARD EVALUATING ROBUSTNESS OF DEEP REIN-FORCEMENT LEARNING WITH CONTINUOUS CONTROL. Weng, T.-W., Dvijotham, K., Uesato, J., Xiao, K., Gowal, S., Stanforth, R., & Kohli, P. (2019). [论文链接]
- 深度强化学习在许多以前很难进行的强化学习任务中都取得了巨大的成功,但是最近的研究表明,类似于分类任务中的深层神经网络,深层RL主体也不可避免地容易受到对抗性干扰。 先前的工作主要集中在无模型的广告攻击和具有离散动作的代理上。 在这项工作中,我们研究了具有对抗性攻击的深层RL中的连续控制主体问题,并基于学习的模型动力学提出了第一个两步算法。 在各种MuJoCo域(Cartpole,Fish,Walker,Humanoid)上的大量实验表明,我们提出的框架在降低代理性能以及将代理驱动到不安全状态方面比无模型攻击基准有效得多。
STRUCTURED OBJECT-AWARE PHYSICS PREDICTION FOR VIDEO MODELING AND PLANNING. Kossen, J., Stelzner, K., Hussing, M., Voelcker, C., & Kersting, K. (2019). [论文链接]
- 当人们观察物理系统时,他们可以轻松地定位物体,了解其相互作用并预测未来的行为。 然而,对于计算机而言,以无人监督的方式从视频中学习此类模型是尚未解决的搜索问题。 在本文中,我们介绍了STOVE,这是一种新颖的视频状态空间模型,可明确说明物体及其位置,速度和相互作用的原因。 它是通过以组合的方式将图像模型和动力学模型组合在一起而构造的,并且通过将动力学模型用于推理,加速和规范化训练来改进以前的工作。 STOVE可以预测经过数千步具有令人信服的身体行为的视频,胜过以前的非监督模型,甚至可以达到监督基线的性能。 我们进一步证明了我们的模型作为仿真器的优势,该仿真器用于在具有大量交互对象的任务中进行基于样本的高效模型控制。
1个
- 当人们观察物理系统时,他们可以轻松地定位物体,了解其相互作用并预测未来的行为。 然而,对于计算机而言,以无人监督的方式从视频中学习此类模型是尚未解决的搜索问题。 在本文中,我们介绍了STOVE,这是一种新颖的视频状态空间模型,可明确说明物体及其位置,速度和相互作用的原因。 它是通过以组合的方式将图像模型和动力学模型组合在一起而构造的,并且通过将动力学模型用于推理,加速和规范化训练来改进以前的工作。 STOVE可以预测经过数千步具有令人信服的身体行为的视频,胜过以前的非监督模型,甚至可以达到监督基线的性能。 我们进一步证明了我们的模型作为仿真器的优势,该仿真器用于在具有大量交互对象的任务中进行基于样本的高效模型控制。
INFINITE-HORIZON OFF-POLICY POLICY EVALUATION WITH MULTIPLE BEHAVIOR POLICIES. Chen, X., Wang, L., Hang, Y., Ge, H., & Zha, H. (2019). [论文链接]
- 当轨迹数据由多个行为策略生成时,我们将考虑策略外策略评估。 最近的工作表明,在无限期的背景下,国家或国家行动的平稳分布校正对离岸政策评估起着关键作用。 我们提出了估计混合策略(EMP),这是一种与策略无关的方法,可以准确地估计这些数量。 通过仔细的分析,我们表明EMP产生了减少的方差估计值,用于估计状态平稳分布校正,同时它还提供了有用的归纳偏差,用于估计状态作用平稳分布校正。 在连续和离散环境下的大量实验中,我们证明了与现有技术方法相比,我们的算法可显着提高准确性。
1个
- 当轨迹数据由多个行为策略生成时,我们将考虑策略外策略评估。 最近的工作表明,在无限期的背景下,国家或国家行动的平稳分布校正对离岸政策评估起着关键作用。 我们提出了估计混合策略(EMP),这是一种与策略无关的方法,可以准确地估计这些数量。 通过仔细的分析,我们表明EMP产生了减少的方差估计值,用于估计状态平稳分布校正,同时它还提供了有用的归纳偏差,用于估计状态作用平稳分布校正。 在连续和离散环境下的大量实验中,我们证明了与现有技术方法相比,我们的算法可显着提高准确性。
MAKING EFFICIENT USE OF DEMONSTRATIONS TO SOLVE HARD EXPLORATION PROBLEMS. Gulcehre, C., Le Paine, T., Shahriari, B., Denil, M., Hoffman, M., Soyer, H., … Wang, Z. (2019). [论文链接]
- 本文介绍了R2D3,它是一种可以有效利用演示来解决在初始条件高度可变的部分可观察环境中解决硬勘探问题的代理。 我们还介绍了包含这三个属性的八个任务套件,并显示了R2D3可以解决其他一些现有技术方法(无论有无演示)都无法在数百亿个成功轨迹之后看到的几个任务 探索步骤。
1个
- 本文介绍了R2D3,它是一种可以有效利用演示来解决在初始条件高度可变的部分可观察环境中解决硬勘探问题的代理。 我们还介绍了包含这三个属性的八个任务套件,并显示了R2D3可以解决其他一些现有技术方法(无论有无演示)都无法在数百亿个成功轨迹之后看到的几个任务 探索步骤。
VariBAD: A Very Good Method for Bayes-Adaptive Deep RL via Meta-Learning. Zintgraf, L., Shiarlis, K., Igl, M., Schulze, S., Gal, Y., Hofmann, K., & Whiteson, S. (2019). [论文链接]
- 在未知环境中权衡探索和开发是最大程度地提高学习期间的预期回报的关键。 一种贝叶斯最佳策略,该策略以最佳方式进行操作,不仅取决于环境状态,还取决于智能体对环境的不确定性,决定其行动。 但是,除了最小的任务外,计算贝叶斯最优策略是很棘手的。 在本文中,我们介绍了变分贝叶斯自适应深度RL(variBAD),这是一种在未知环境中进行元学习以进行近似推理的方法,并直接在操作选择过程中纳入了不确定性。 在网格世界中,我们说明了variBAD如何根据任务不确定性执行结构化的在线探索。
KEEP DOING WHAT WORKED: BEHAVIOR MODELLING PRIORS FOR OFFLINE REIN-FORCEMENT LEARNING. Siegel, N. Y., Springenberg, T., Berkenkamp, F., Abdolmaleki, A., Neunert, M., Lampe, T., … Deepmind, M. R. (2019). [论文链接]
- 非政策强化学习算法有望适用于只有固定的环境交互数据集(批次)可用且无法获得新经验的环境。 此属性使这些算法对诸如机器人控制之类的现实世界问题具有吸引力。 但是,实际上,标准的非策略算法在批量设置中无法进行连续控制。 在本文中,我们提出了一个简单的解决方案。 它允许使用由任意行为策略生成的数据,并使用获悉的先验知识-优势加权行为模型(ABM)-将RL策略偏向于先前已执行且可能会成功完成新任务的行为。 我们的方法可以看作是对批处理RL的最新工作的扩展,它可以从冲突的数据源中进行稳定的学习。 我们发现各种RL任务的竞争基准都有改进-包括标准连续控制基准和针对模拟和现实机器人的多任务学习。 可以从以下网址获得视频:https://sites.google.com/view/behavior-modelling-priors。
1个
- 非政策强化学习算法有望适用于只有固定的环境交互数据集(批次)可用且无法获得新经验的环境。 此属性使这些算法对诸如机器人控制之类的现实世界问题具有吸引力。 但是,实际上,标准的非策略算法在批量设置中无法进行连续控制。 在本文中,我们提出了一个简单的解决方案。 它允许使用由任意行为策略生成的数据,并使用获悉的先验知识-优势加权行为模型(ABM)-将RL策略偏向于先前已执行且可能会成功完成新任务的行为。 我们的方法可以看作是对批处理RL的最新工作的扩展,它可以从冲突的数据源中进行稳定的学习。 我们发现各种RL任务的竞争基准都有改进-包括标准连续控制基准和针对模拟和现实机器人的多任务学习。 可以从以下网址获得视频:https://sites.google.com/view/behavior-modelling-priors。
META REINFORCEMENT LEARNING WITH AUTONOMOUS INFERENCE OF SUBTASK DEPENDENCIES. Sohn, S., Woo, H., Choi, J., & Lee, H. (2019). [论文链接]
- Michigan, Google Brain
- 我们提出并解决了一个新的小样本RL问题,其中任务以子任务图为特征,该子任务图描述了对于智能体来说未知的一组子任务及相互间的依赖关系。智能体需要在适应阶段的几个循环中快速适应任务,以使测试阶段的收益最大化。我们没有直接学习元策略,而是开发了Meta-learner with Subtask Graph Inference(MSGI),通过与环境交互来推断任务的潜在参数,并在给定潜在参数的情况下最大化回报。 为了促进学习,我们采用了内在奖励,这种奖励是受到用于鼓励有效探索的upper confidence bound(UCB)的启发。 我们在两个grid-world domains和StarCraft II环境上的实验结果表明,与现有的元RL和分层RL方法相比,该方法能够准确地推断潜在任务参数,并且能够更有效地进行自适应。https://bit.ly/msgi-videos可看到demo视频。
Dynamics-aware Embeddings. Whitney, W., Agarwal, R., Cho, K., & Gupta, A. (2019). [论文链接]
- 在本文中,我们考虑了自我监督的表示学习,以提高强化学习(RL)中的样本效率。 我们提出了一种前向预测目标,用于同时学习状态和动作序列的嵌入。 这些嵌入捕获了环境动态的结构,从而实现了有效的策略学习。 我们证明,仅通过动作嵌入,就可以提高无模型RL在低维状态控制下的采样效率和峰值性能。 通过结合状态和动作嵌入,我们可以在仅1-2百万个环境步骤中从像素观察中高效学习目标条件连续控制的高质量策略。
1个
- 在本文中,我们考虑了自我监督的表示学习,以提高强化学习(RL)中的样本效率。 我们提出了一种前向预测目标,用于同时学习状态和动作序列的嵌入。 这些嵌入捕获了环境动态的结构,从而实现了有效的策略学习。 我们证明,仅通过动作嵌入,就可以提高无模型RL在低维状态控制下的采样效率和峰值性能。 通过结合状态和动作嵌入,我们可以在仅1-2百万个环境步骤中从像素观察中高效学习目标条件连续控制的高质量策略。
NEVER GIVE UP: LEARNING DIRECTED EXPLORATION STRATEGIES. Puigdomènech Badia, A., Sprechmann, P., Vitvitskyi, A., Guo, D., Piot, B., Kapturowski, S., … Blundell, C. (2019). [论文链接]
- 我们建议一个强化学习代理,通过学习一系列定向探索政策来解决艰苦的探索游戏。 我们根据代理人的最新经验,使用k近邻来构造基于情节记忆的内在奖励,以训练定向探索策略,从而鼓励代理人反复访问其环境中的所有状态。 使用自我监督的逆动力学模型来训练最近邻居查找的嵌入,从而将新颖性信号偏向于代理可以控制的范围。 我们采用通用价值函数逼近器(UVFA)框架,以相同的神经网络同时学习许多定向勘探策略,并且在勘探和开发之间进行了折衷。 通过将相同的神经网络用于不同程度的勘探/开发,可以从主要探索性政策中产生转移,从而产生有效的利用性政策。 可以将提出的方法与现代分布式RL代理一起运行,该代理从在不同环境实例上并行运行的许多参与者收集大量经验。 在Atari-57套件的所有艰苦探索中,我们的方法使基本代理的性能翻了一番,同时在其余游戏中保持了很高的分数,获得了人类标准化分数的中位数为1344.0%。 值得注意的是,所提出的方法是第一个在“陷阱”游戏中获得非零奖励(平均分数为8,400)的算法! 无需使用演示或手工制作的功能。
1个
- 我们建议一个强化学习代理,通过学习一系列定向探索政策来解决艰苦的探索游戏。 我们根据代理人的最新经验,使用k近邻来构造基于情节记忆的内在奖励,以训练定向探索策略,从而鼓励代理人反复访问其环境中的所有状态。 使用自我监督的逆动力学模型来训练最近邻居查找的嵌入,从而将新颖性信号偏向于代理可以控制的范围。 我们采用通用价值函数逼近器(UVFA)框架,以相同的神经网络同时学习许多定向勘探策略,并且在勘探和开发之间进行了折衷。 通过将相同的神经网络用于不同程度的勘探/开发,可以从主要探索性政策中产生转移,从而产生有效的利用性政策。 可以将提出的方法与现代分布式RL代理一起运行,该代理从在不同环境实例上并行运行的许多参与者收集大量经验。 在Atari-57套件的所有艰苦探索中,我们的方法使基本代理的性能翻了一番,同时在其余游戏中保持了很高的分数,获得了人类标准化分数的中位数为1344.0%。 值得注意的是,所提出的方法是第一个在“陷阱”游戏中获得非零奖励(平均分数为8,400)的算法! 无需使用演示或手工制作的功能。
ON THE INTERACTION BETWEEN SUPERVISION AND SELF-PLAY IN EMERGENT COMMUNICATION. Lowe, R., Gupta, A., Foerster, J., Kiela, D., & Pineau, J. (2019). [论文链接]
- 教人工代理使用自然语言的一种有前途的方法包括使用在环培训。 但是,最近的工作表明,当前的机器学习方法数据效率太低,无法从头开始以这种方式进行训练。 在本文中,我们研究了两类学习信号之间的关系,其最终目的是提高样本效率:通过监督学习来模仿人类语言数据,并通过自我玩耍在模拟的多主体环境中最大化报酬(已完成)。 (在紧急通信中),并为使用这两种信号的算法引入术语监督自播放(S2P)。 我们发现,通过在人类数据上进行有监督的学习,然后通过自学的方式进行的第一个培训代理的表现要好于相反的情况,这表明从头开始出现语言是无益的。 然后,我们根据经验研究各种S2P计划,这些计划从两种环境下的监督学习开始:具有符号输入的Lewis信号游戏和具有自然语言描述的基于图像的参照游戏。 最后,我们介绍了基于群体的S2P方法,与单代理方法相比,它进一步提高了性能。11
STATE ALIGNMENT-BASED IMITATION LEARNING. Liu, F., Ling, Z., Mu, T., & Su, H. (2019). [论文链接]
- 考虑一个模仿者和专家具有不同动力学模型的模仿学习问题。 当前大多数模仿学习方法失败,因为它们专注于模仿动作。 我们提出了一种基于状态对齐的新型模仿学习方法,以训练模仿者在专家演示中尽可能遵循状态序列。 国家的协调来自本地和全球的观点,我们通过定期的政策更新目标将它们整合为强化学习框架。 我们展示了我们的方法在标准模仿学习设置和专家和模仿者具有不同动力学模型的模仿学习设置上的优势。
Discriminative Particle Filter Reinforcement Learning for Complex Partial Observations. Ma, X., Karkus, P., Hsu, D., Lee, W. S., & Ye, N. (2020). [论文链接]
- 深度强化学习在诸如Atari,Go等复杂游戏的决策中是成功的。但是,现实世界中的决策通常需要推理,并从复杂的视觉观察中提取部分信息。本文介绍了判别式粒子滤波强化学习(DPFRL),这是一种用于复杂局部观测的新型强化学习框架。 DPFRL对神经网络策略中的可微分粒子过滤器进行编码,以进行显式推理,并随时间进行部分观察。粒子过滤器使用经过学习的判别式更新来保持信念,该判别式更新经过端到端的决策训练。我们证明,使用判别式更新而不是标准生成模型可以显着提高性能,特别是对于具有复杂视觉观察的任务,因为他们避免了建模与决策无关的复杂观测的困难。此外,为了从粒子置信度中提取特征,我们基于矩生成函数提出了一种新型的置信度特征。在现有的POMDP RL基准测试《 Flickering Atari》游戏中,DPFRL优于最新的POMDP RL模型;在本文中介绍的新的,更具挑战性的POMDP RL基准测试《 Natural Flickering Atari Games》中,DPFRL优于最新的POMDP RL模型。此外,DPFRL在人居环境中使用真实数据进行视觉导航时表现出色。该代码可在线获得1。
1个
- 深度强化学习在诸如Atari,Go等复杂游戏的决策中是成功的。但是,现实世界中的决策通常需要推理,并从复杂的视觉观察中提取部分信息。本文介绍了判别式粒子滤波强化学习(DPFRL),这是一种用于复杂局部观测的新型强化学习框架。 DPFRL对神经网络策略中的可微分粒子过滤器进行编码,以进行显式推理,并随时间进行部分观察。粒子过滤器使用经过学习的判别式更新来保持信念,该判别式更新经过端到端的决策训练。我们证明,使用判别式更新而不是标准生成模型可以显着提高性能,特别是对于具有复杂视觉观察的任务,因为他们避免了建模与决策无关的复杂观测的困难。此外,为了从粒子置信度中提取特征,我们基于矩生成函数提出了一种新型的置信度特征。在现有的POMDP RL基准测试《 Flickering Atari》游戏中,DPFRL优于最新的POMDP RL模型;在本文中介绍的新的,更具挑战性的POMDP RL基准测试《 Natural Flickering Atari Games》中,DPFRL优于最新的POMDP RL模型。此外,DPFRL在人居环境中使用真实数据进行视觉导航时表现出色。该代码可在线获得1。
Episodic Reinforcement Learning With Associiative Memory. Zhu, G., Lin, Z., Yang, G., & Zhang, C. (2020). [论文链接]
- 样本效率一直是深度强化学习的主要挑战之一。已经提出了非参数情景控制,通过快速锁定先前成功的策略来加速参数强化学习。但是,以前的情景强化学习工作忽略了状态之间的关系,只将经验存储为无关的项目。为了提高强化学习的样本效率,我们提出了一种新颖的框架,即带有联想记忆的情节强化学习(ER-LAM),该框架将相关的经验轨迹相关联,以实现推理有效策略。我们基于状态转移在内存中的状态之上构建图形,并开发一种有效的反向轨迹传播策略,以允许值通过图形快速传播。我们使用非参数联想记忆作为参数强化学习模型的早期指导。 Atari游戏的结果表明,我们的框架具有显着更高的采样效率,并且胜过了最新的情节式强化学习模型。
1个
- 样本效率一直是深度强化学习的主要挑战之一。已经提出了非参数情景控制,通过快速锁定先前成功的策略来加速参数强化学习。但是,以前的情景强化学习工作忽略了状态之间的关系,只将经验存储为无关的项目。为了提高强化学习的样本效率,我们提出了一种新颖的框架,即带有联想记忆的情节强化学习(ER-LAM),该框架将相关的经验轨迹相关联,以实现推理有效策略。我们基于状态转移在内存中的状态之上构建图形,并开发一种有效的反向轨迹传播策略,以允许值通过图形快速传播。我们使用非参数联想记忆作为参数强化学习模型的早期指导。 Atari游戏的结果表明,我们的框架具有显着更高的采样效率,并且胜过了最新的情节式强化学习模型。
SUB-POLICY ADAPTATION FOR HIERARCHICAL REINFORCEMENT LEARNING. Li, A. C., Florensa, C., Clavera, I., & Abbeel, P. (2019). [论文链接]
- UCB
- 分层强化学习是一种可解决具有稀疏奖励的长期决策问题的有效方法。不幸的是,大多数方法仍然使低级技能的获取过程与控制新任务中技能的高级训练分离开来。保持技能固定会导致迁移设置中出现明显的局部最优。在这项工作中,我们提出了一种新颖的算法,用于发现一组技能,在接受新任务训练时,仍然可以同高级技能一起不断地适应。 我们的主要贡献是双重的。首先,我们推导了一个新的具有无偏潜在依赖baseline的分层策略梯度,并引入了Hierarchical Proximal Policy Optimization(HiPPO),一种有效地联合训练分层结构各个级别的on-policy方法。 其次,我们提出了一种训练时间抽象的方法,提高了所获得的技能对环境变化的鲁棒性。代码和视频可以从https://sites.google.com/view/hippo-rl找到。
LEARNING NEARLY DECOMPOSABLE VALUE FUNC-TIONS VIA COMMUNICATION MINIMIZATION. Wang, T., Wang, J., Zheng, C., & Zhang, C. (2019). [论文链接]
- 增强学习在多智能体设置中遇到了主要挑战,例如可伸缩性和非平稳性。最近,value function分解学习已成为解决协作多智能体系统中这些挑战的一种有效的方法。但是,现有方法一直专注于学习完全去中心化的value function,这对于需要通信的任务而言效率不高。为了解决这一局限性,本文提出了一种新的框架,用于通过通信最小化学习nearly decomposable Q-functions(NDQ),智能体大部分时间都在自己行动,但偶尔会向其他智能体发送消息以进行有效的协调。该框架通过引入两个信息论正则化项,将value function分解学习和通信学习结合在一起。这些正则化函数使智能体的动作选择和通信消息之间的互信息最大化,同时使智能体之间的消息熵最小。我们展示了如何以易于与现有的value function分解方法(例如QMIX)集成的方式来优化这些正则项。最后,我们证明,在《星际争霸》单位的micromanagement benchmark上,我们的框架明显优于baseline方法,并允许我们在不牺牲性能的情况下切断了80%以上的通信。有关实验的视频,请访问https://sites.google.com/view/ndq。
LEARNING TO COORDINATE MANIPULATION SKILLS VIA SKILL BEHAVIOR DIVERSIFICATION. Lee, Y., Yang, J., & Lim, J. J. (2019). [论文链接]
- 当完成一个复杂的操纵任务时,人们经常将任务分解为身体各个部分的子技能,独立地练习这些子技能,然后一起执行这些子技能。同样,具有多个末端执行器的机器人可以通过协调每个末端执行器的子技能来执行复杂的任务。为了实现技能的时间和行为协调,我们提出了一个模块化框架,该框架首先通过skill behavior diversification分别训练每个末端执行器的子技能,然后学习使用技能的多种行为来协调末端执行器。我们证明了我们提出的框架能够有效地协调技能,以解决具有挑战性的协作控制任务,例如捡起一根长棒,在用两个机械手推动容器的同时在容器内放置一个块以及用两个蚂蚁推动容器。 视频和代码可在https://clvrai.com/coordination上获得。
