摘要
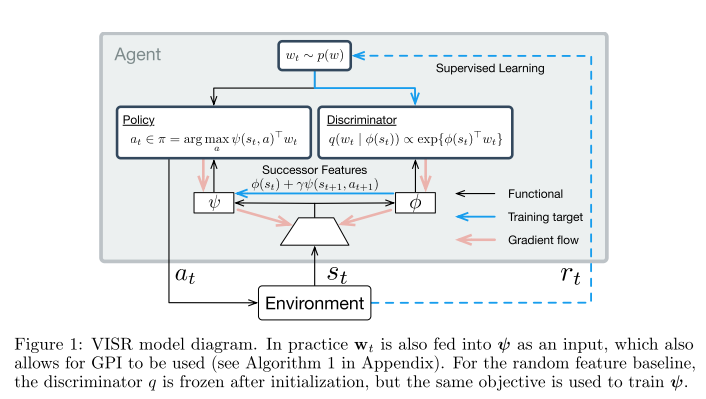
已经确定,张成马尔可夫决策过程可控子空间的多样性行为可以通过奖励与其他policy有区别的policy来训练(Gregor et al., 2016; Eysenbach et al., 2018; Warde-Farley et al., 2018)。但是,这种方法的一个局限性是难以推广到超出可明确学习的有限行为集的范围,而这在后续任务中可能是必需的。Successor features(Dayan, 1993; Barreto et al., 2017)提供了一个吸引人的解决方案,适用于此泛化问题,但需要在某些基础特征空间中将奖励函数定义为线性。在本文中,我们展示了可以将这两种技术结合使用,并且相互可以解决彼此的主要局限。为此,我们引入了Variational Intrinsic Successor FeatuRes(VISR),这是一种新的算法,能够学习可控特征,可通过Successor features框架利用可控特征来提供增强的泛化能力和快速的任务推断能力。我们在全部Atari套件上对VISR进行了实验验证,我们使用了新的设置,其中奖励仅是在漫长的无监督阶段之后才短暂显示。在12场比赛中达到人类水平的表现并超过所有baselines,使我们认为VISR代表了朝着能够从有限的反馈中快速学习的智能体迈出的一步。
论文信息

- 作者:Hansen DeepMind, S., Dabney DeepMind, W., Barreto DeepMind, A., Warde-Farley DeepMind, D., Van de Wiele, T., & Mnih DeepMind, V.
- 出处:ICLR2020 Oral
- 机构:DeepMind
- 关键词:diverse behavior,Successor features
- 论文链接
内容简记
方法